
| 髙橋 誉文 広島市立大学 協力研究員 |
[背景]バイオデータベースに登録されるデータ件数の急増
[問題]類似配列検索の高速化と類似構造検索の高精度化
[貢献]高性能な類似検索手法の提案と評価
(3)蛋白質立体構造データベースから類似構造検索をするには,2つの構造間の構造整列化を繰り返し実施しながら,問合せ構造に類似すると蛋白質構造をデータベースから見つけ出すことが重要となる.構造整列化を実施する方法には,RMSDや動的計画法,CMO問題を解く方法が研究されている.しかしながら,EOを用いた発見的解法には,解の大域的な探索が難しいCMO問題に対して局所解へ陥りやすいという問題点がある.この問題点を解決するために,改良版EOを用いたCMO問題の発見的解法を提案する.評価実験を行った結果,EOによる発見的解法よりも評価の高い最良解が得られた.
[問題]類似配列検索の高速化と類似構造検索の高精度化
[貢献]高性能な類似検索手法の提案と評価
蛋白質は酵素,抗体やホルモンなど,生命活動の生体機能にかかわる重要な物質である.塩基配列(DNAやRNA)を初めとして,アミノ酸配列や蛋白質立体構造などを含むバイオデータベースの構築・利用を前提としたコンピュータ利用は,生命科学・医療および創薬の開発などの発展に大きく貢献するものと考えられてきている.現在,国際的に組織されている主要なデータバンクには,塩基配列データバンクおよび蛋白質立体構造データバンクがあり,日米欧による国際協力体制で運営されている.これらのデータバンクでは,塩基配列を格納する塩基配列データベースおよび蛋白質立体構造を3次元座標配列として格納する蛋白質立体構造データベースをそれぞれ構築している.さらに,これらのデータバンクでは,バイオインフォマティシャンを含む研究者コミュニティの育成を初めとして,データベースの利用を可能にするツールの構築やWeb検索サービスなどを実施してきている.
近年,塩基配列データベースを始めとして,アミノ酸配列データベースや蛋白質立体構造データベースに登録されるデータ件数が急増してきているため,このようなバイオデータベースに対する高性能なデータ処理として類似検索の高速化や高精度化の研究が盛んに行われている.
近年,塩基配列データベースを始めとして,アミノ酸配列データベースや蛋白質立体構造データベースに登録されるデータ件数が急増してきているため,このようなバイオデータベースに対する高性能なデータ処理として類似検索の高速化や高精度化の研究が盛んに行われている.
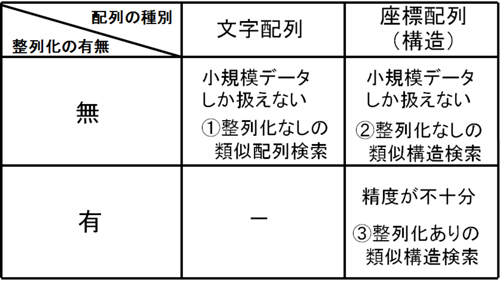
バイオデータベースの高性能なデータ処理の研究には,主として,塩基配列やアミノ酸配列に関する類似配列検索および立体構造に関する類似構造検索の2つに分類される.さらにそれぞれの研究は,索引構造を用いて高速に類似検索を行うアプローチと,整列化を用いて高精度に類似検索を行うアプローチの2つの研究に分類される.このような分類を踏まえ,本研究では,バイオデータベースに対する高性能なデータ処理の実現を目指し,以下の3つの問題点に取り組んだ.
(1)類似配列検索の高速化を目指し,索引構造として文字列の接尾辞木が研究されている.この索引構造の研究では,小規模データを対象としているため,大規模なデータベースを想定した研究が十分に行われていないという問題点がある.この問題点を解決するために,マルチコアCPU上においてメモリ上ではなくディスク上に構築されたディスクベースの接尾辞木を用いた類似配列検索のための高性能な並列化モデルを提案する.評価実験を行い,従来の手法より最大で約35%の高速化を達成し,効率の良い類似配列検索が可能となった.
(2)類似構造検索の高速化を目指し,座標配列の接尾辞木が研究されている.この索引構造の研究では,小規模データを対象としているため,大規模なデータベースを想定した研究が十分に行われていないという問題点がある.この問題点を解決するために,幾何学的接尾辞木をメモリ上ではなくディスク上に構築する方法と,幾何学的接尾辞木の構築と検索を並列化する方法を提案する.評価実験を行った結果,従来手法よりも高速な幾何学的接尾辞木の構築と検索を行うことができた.(3)蛋白質立体構造データベースから類似構造検索をするには,2つの構造間の構造整列化を繰り返し実施しながら,問合せ構造に類似すると蛋白質構造をデータベースから見つけ出すことが重要となる.構造整列化を実施する方法には,RMSDや動的計画法,CMO問題を解く方法が研究されている.しかしながら,EOを用いた発見的解法には,解の大域的な探索が難しいCMO問題に対して局所解へ陥りやすいという問題点がある.この問題点を解決するために,改良版EOを用いたCMO問題の発見的解法を提案する.評価実験を行った結果,EOによる発見的解法よりも評価の高い最良解が得られた.
(2016年6月10日受付)