
| 榎 美紀 日本アイ・ビー・エム(株) 東京基礎研究所 |
[背景]大規模データをリアルタイムに,高速に処理する基盤の必要性
[問題]リアルタイム・オフライン分析を同時に備えた基盤の処理性能は未検討
[貢献]リアルタイム・オフライン分析の使い分けの検討とデータアクセス最適化
[問題]リアルタイム・オフライン分析を同時に備えた基盤の処理性能は未検討
[貢献]リアルタイム・オフライン分析の使い分けの検討とデータアクセス最適化
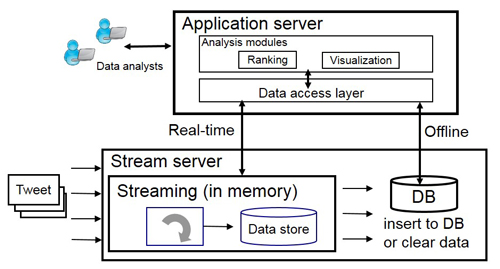
近年,位置情報・気象・ソーシャル・センサデータなど,さまざまなデバイスから日々発信され続けている膨大な量のデータを利用して関連性を見つけたり,変化を検知したりと,様々な観点から分析する要求は年々高まっている.それらを実現するための処理基盤は大規模なデータをリアルタイムに,また高速に扱えることが重要となる.このようなストリームデータをリアルタイムに分析するため,2000年以降ストリームデータ処理を主にしたDSMS(Data Stream Management System)が登場した.従来のDBMS(DataBase Management System)と異なり,連続的に発信されるデータを対象にリアルタイムにデータ加工や分析結果を返し続けるシステムである.
DSMSは流れてくるストリームデータに対して,連続的にクエリが実行される.データへの問合せ部分に着目したとき,あらかじめ指定したウィンドウと呼ばれる単位にデータを区切り,その範囲内に到着したデータに対してクエリの演算を施すという特徴がある. DSMSで演算処理された後のデータは,一般的に破棄されていた.それは現在の状態における何らかの演算結果が重要であり,ストリーム処理システムはそのような要件を満たすためのシステムであるからである.また,ストリームデータはリアルタイムに到着し続けるため,全データをストレージに格納することは現実的ではなかった.ところが,近年のストレージの格納量の大規模化にも伴い,ストリームデータもそのままストレージに格納され,それをオフラインで分析対象にすることも増えてきた.しかしながら,ストリームデータのリアルタイムの分析とストレージに格納したオフラインでの分析を同時に考えたシステムは検討されていない.
そこで本研究では,大規模リアルタイムデータの一つであるソーシャルメディアデータを対象として,リアルタイムなストリームデータを逐次的にストリーム処理する機構と,蓄積されたデータを処理する機構を兼ね備えたリアルタイム分析システムを提案する.ストリームデータのリアルタイム性の収束のタイミングを議論し,リアルタイム分析とオフライン分析との使い分けの手法を検討する.
逐次的にストリーム処理をする部分については,できるだけフレッシュなデータをストリーム処理内に維持するために,各メッセージの流行が収束するタイミングを拡散モデルを用いて早期に推定し,時間ウィンドウ幅をカスタマイズしてメンテナンスする手法を提案し,Twitterの実データを用いてその効果を示した.また,ソーシャルメディアには,ある出来事が突然大きく話題になると瞬間的に多くのユーザが一斉にメッセージを発信し出し,バースト状態を起こす特徴がある.このようなデータバースト時のクエリの応答時間の劣化を回避するため,各メッセージに付随する情報に着目して重要度を計算し,重要度が低いと判断されたメッセージをフィルタリングして処理するデータ量をコントロールする手法を提案した.これにより,従来のランダムなフィルタリングと比較して,同程度のサンプリング量において,問合せ結果の精度を高く維持しながら,問合せ時間をより短く処理できていることを示した.
DSMSは流れてくるストリームデータに対して,連続的にクエリが実行される.データへの問合せ部分に着目したとき,あらかじめ指定したウィンドウと呼ばれる単位にデータを区切り,その範囲内に到着したデータに対してクエリの演算を施すという特徴がある. DSMSで演算処理された後のデータは,一般的に破棄されていた.それは現在の状態における何らかの演算結果が重要であり,ストリーム処理システムはそのような要件を満たすためのシステムであるからである.また,ストリームデータはリアルタイムに到着し続けるため,全データをストレージに格納することは現実的ではなかった.ところが,近年のストレージの格納量の大規模化にも伴い,ストリームデータもそのままストレージに格納され,それをオフラインで分析対象にすることも増えてきた.しかしながら,ストリームデータのリアルタイムの分析とストレージに格納したオフラインでの分析を同時に考えたシステムは検討されていない.
そこで本研究では,大規模リアルタイムデータの一つであるソーシャルメディアデータを対象として,リアルタイムなストリームデータを逐次的にストリーム処理する機構と,蓄積されたデータを処理する機構を兼ね備えたリアルタイム分析システムを提案する.ストリームデータのリアルタイム性の収束のタイミングを議論し,リアルタイム分析とオフライン分析との使い分けの手法を検討する.
逐次的にストリーム処理をする部分については,できるだけフレッシュなデータをストリーム処理内に維持するために,各メッセージの流行が収束するタイミングを拡散モデルを用いて早期に推定し,時間ウィンドウ幅をカスタマイズしてメンテナンスする手法を提案し,Twitterの実データを用いてその効果を示した.また,ソーシャルメディアには,ある出来事が突然大きく話題になると瞬間的に多くのユーザが一斉にメッセージを発信し出し,バースト状態を起こす特徴がある.このようなデータバースト時のクエリの応答時間の劣化を回避するため,各メッセージに付随する情報に着目して重要度を計算し,重要度が低いと判断されたメッセージをフィルタリングして処理するデータ量をコントロールする手法を提案した.これにより,従来のランダムなフィルタリングと比較して,同程度のサンプリング量において,問合せ結果の精度を高く維持しながら,問合せ時間をより短く処理できていることを示した.
(2016年6月14日受付)