製造データ活用による試験判定基準の最適化─量産工場の製造データ分析の事例から─
1.はじめに
近年,さまざまなモノに通信機能を持たせ,モノをインターネットへ接続させるIoT(Internet of Things)が注目を集めている.IoTは,デバイスやセンサ,ネットワークの高度化に伴い,製造業,家電や自動車,医療や農業など,さまざまな分野で広がりを見せている.
その中でも,製造業では,あらゆる場面でさまざまなセンサを使い,設計情報や生産時のパラメータ,試験結果などの情報を収集・活用する取り組みがなされている.国外では,IoT推進・標準化関連のアライアンスが多数立ち上がっている.特に著名なものとして,アメリカ政府とGE(General Electric Company)を中心としたIIC(Industrial Internet Consortium)[1]や,ドイツ政府が牽引するIndustrie 4.0 [2]がある.
我が国においても,政府が牽引するIoT推進コンソーシアムや,製造業が中心であるIVI(Industrial Value Chain Initiative)など,IoT推進・標準化関連のアライアンスが結成されている.そして,各アライアンスに属する製造業やIT企業より,設備の予防保全・非効率運転の防止,品質管理の高度化など,さまざまなIoT活用の事例が発表されている[3].
本稿では,製造業におけるIoT活用事例について紹介する.第2章では,工場におけるデータ活用の概要と部品組立工場における試験判定基準の課題を述べる.第3章では,筆者らが開発した試験判定基準を最適化する方式について述べる.第4章では,実証実験として実際の製造データへ方式を適用した結果について述べる.第5章では実証実験によって得られた知見について述べ,最後に第6章で本稿をまとめる.
2.工場におけるデータ分析
2.1 製造業におけるデータ活用
製造現場ではさまざまなデータが取得される.本稿では,この製造現場で取得されるデータを「工場データ」と呼ぶ.工場データのうち,設備より取得されるデータは,2種類に分類できる.以下にそれらのデータと,代表的な活用例について述べる.
1つ目は,設備の温度や消費電力,振動など一定周期で取得される時系列データである.本稿では,この時系列データを「設備データ」と呼ぶ.設備データの活用には,設備故障などの不具合時のデータから法則を抽出して不具合の発生時期を予測し事前に保守を行う設備予防保全がある.また,蓄積された過去のデータに基づく消費エネルギー量の予測がある.
2つ目は,製品製造時のタクトタイム,品質試験結果,製造条件,使用した部品ロットなど,製品製造の都度取得されるデータである.本稿では,この製造時に取得されるデータを「製造データ」と呼ぶ.製造データの活用には,試験結果を製造条件や部品ロットと紐付けて因果関係を抽出することによる,製品品質の改善がある.また,製品品質の改善のほか,タクトタイムを統計的な手法で処理することによる製造効率の改善がある.
例に挙げたように,工場データの活用目的は多岐にわたる[4].そして,これらのデータ活用取り組みは,主に「①収集・蓄積」「②可視化」「③予測」「④効率化」「⑤ビジネスモデル転換」の5ステップに分類される[5].
本稿では,生産性の向上,部品の原価低減といった「効率化」のために,「製造データ」を活用した事例について紹介する.2.2 工場データの取得
工場データの活用には,データを収集・蓄積できる仕組みが必要である.まずデータ収集のため,工場設備にはセンサなどの装置が必要となる.また,拠点やラインを横断してデータを収集するため,ネットワークが必要となる.そして,収集した工場データを集約して管理・蓄積するため,データベースなどのシステムが必要である.
システムに蓄積されたデータを活用するため,アプリケーションが必要になる.このアプリケーションは,システム上に搭載されることもあるが,用途によっては工場設備上に実装されることもある.
三菱電機では,ファクトリーオートメーションのトータルソリューションであるe-F@ctoryにより,ネットワーク化した工場を実現している.そして,蓄積された工場データを活用して,不具合発生時の要因推定や,品質管理,保守運用コストの削減,生産実績の見える化,設備稼働率の向上といった効率化を実現してきた.
2.3 製造データを活用した試験判定
本節では,今回対象とした部品組立工場と,そこで取得される製造データを説明する.この工場では,製造データに基づき自動で製品の合否を判定している.
分析対象の工場では,さまざまな部品を組み合わせて量産品を製造している.工場は,部品製造ライン,製品組立ラインなど多数のラインで構成されており,各ラインでは多種多様な製品・部品が製造される.1つのラインは,複数の工程で構成されており, 1つの工程ではさまざまな計測がなされる.計測には,製造時のパラメータを計測する「計測項目」と,試験時のパラメータを取得して合否を判定する「試験項目」がある.本稿では,計測項目と試験項目で取得されるパラメータをまとめて「測定値」と呼ぶこととする.
工場を流れる製品・部品には,システムによって固有の識別ID(以降,製番)がそれぞれ付与されており,個体管理されている.各製品・部品が通過したラインや工程,計測項目・試験項目ごとの測定値がシステムによって管理されている.
また,試験項目には,測定値の正常範囲として上限値,下限値のいずれか,もしくは両方が指定されている.本稿では,この正常範囲を「試験判定基準」と呼ぶこととする.製品の合否は,試験項目にて取得された測定値が試験判定基準の範囲内である場合のみ,合格となる.また,試験基準は製品の種類によって異なるため,試験項目には製品の種類に対応する試験判定基準が設定されている.試験判定基準についてもシステムによって管理されている.
製品が工程に投入され,合否が判定されるまでの流れを述べる.図1に工場における工程のイメージを示す.それぞれの製品に対して,計測項目にて測定値が取得され,試験項目にて測定値および合否判定結果が取得される.工程に含まれるすべての試験項目で合格した製品のみ,次の工程へと進む.
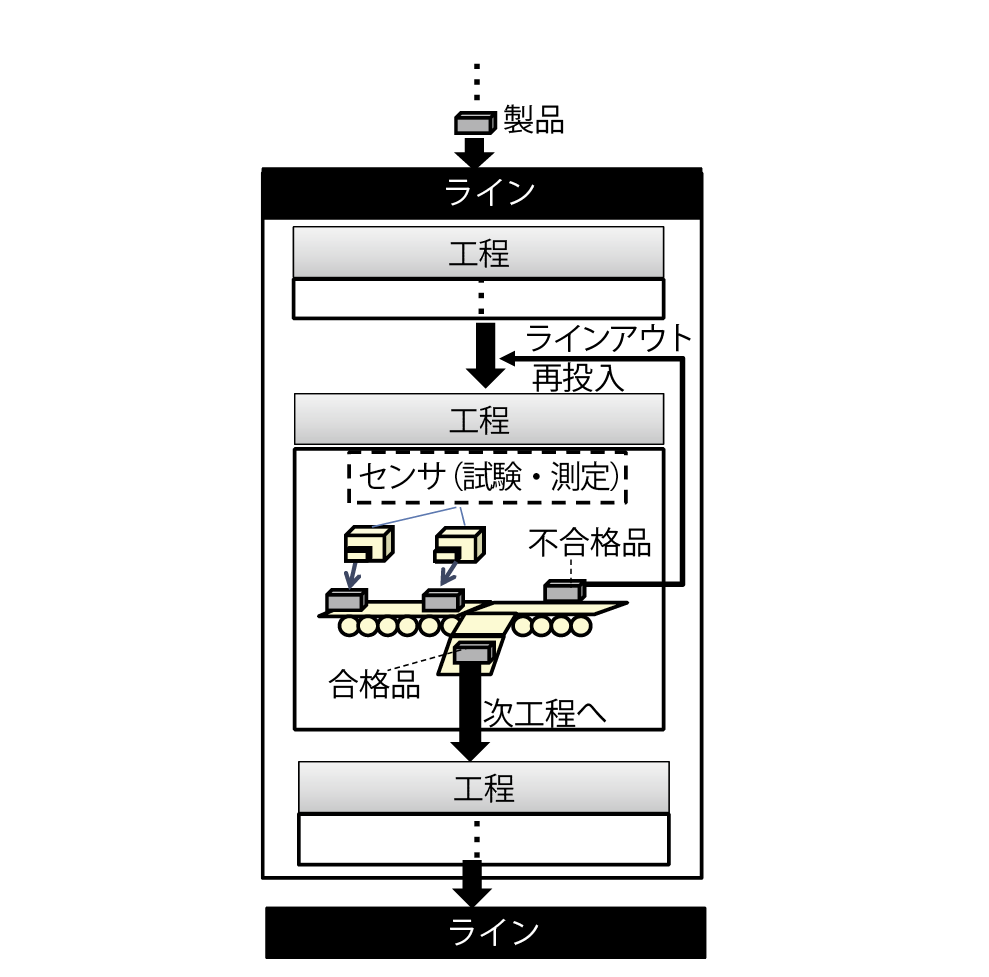
もし,製品がいずれかの試験項目にて不合格と判定された場合,ラインまたは工程から一度除外される.そして,人手による再調整の後,再びラインや工程へと投入される.再調整を何度か繰り返しても不合格となる場合は,不良品とみなされ廃棄される.
2.4 試験判定基準の課題
本節では,現在実施されている試験判定基準の設定方法および,その課題について述べる.
試験判定基準は,主に次の2つの考え方で設定される.1つ目は,製品の性能や,物理モデル,設計者の知見に基づき設定される.2つ目は,製造設備の立上げ前に,製品試作機の投入評価により設定される.
だが,試験判定基準は,必ずしも常に最適な値が設定されているとは限らない.たとえば,複数台の試作機を評価することで設定された試験判定基準は,その試作機の特性に影響されてしまう.また,設計者の知見に基づいて設定された場合であっても,工場設備の摩耗や,設備ごとの器差により,想定される測定値と実測値に差異が生じることがある.
そのため試験判定基準は,定期的に調整されることがある.また,試験不合格品の急増などの不具合発生や,設備のメンテナンス・リプレースなどの仕様変更時にも調整されることがある.この調整は,現場の責任者や品質保証担当者らの現場や製品知識や,品質管理手法に基づいて実施される.代表的な品質管理手法として,統計的手法のQC7つ道具や,工程能力指数(process capability index)が用いられる[6][7].
試験判定基準が最適でないときや,試験判定基準の調整に関する代表的な課題を3点述べる.
- 緩すぎる試験判定基準による生産性の低下
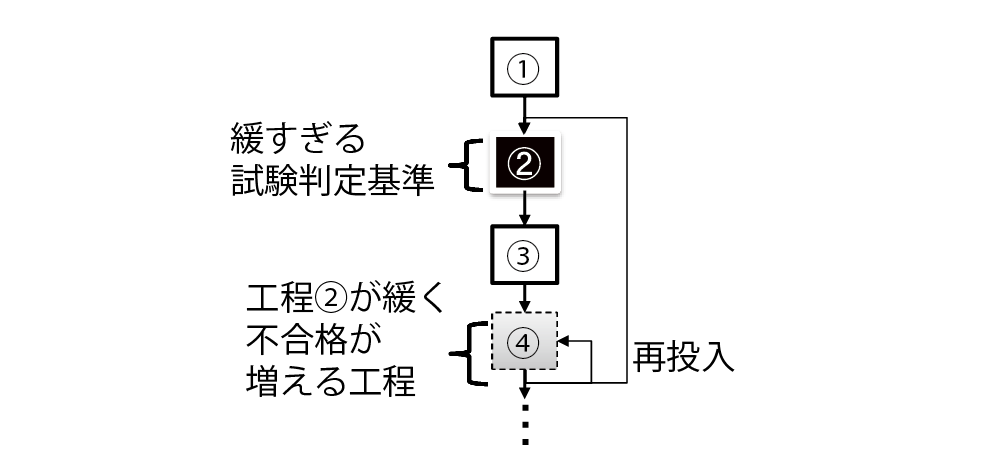
ある工程における試験項目の結果が,それよりも後工程の試験項目における合否判定結果に影響を与えることがある.そのような関係がある場合において,前工程の試験項目の試験判定基準が緩いと,後工程にて不合格が増加する.そのため,再投入による製造時間の増加や,製品廃棄の増加によって歩留が低下するなど,生産性が低下する.
図2は,前工程(工程2)における試験項目の試験判定基準が緩いため,後工程(工程4)にて製品が不合格となり,再投入が多発する例である.
- 厳しすぎる試験判定基準による過剰な排除
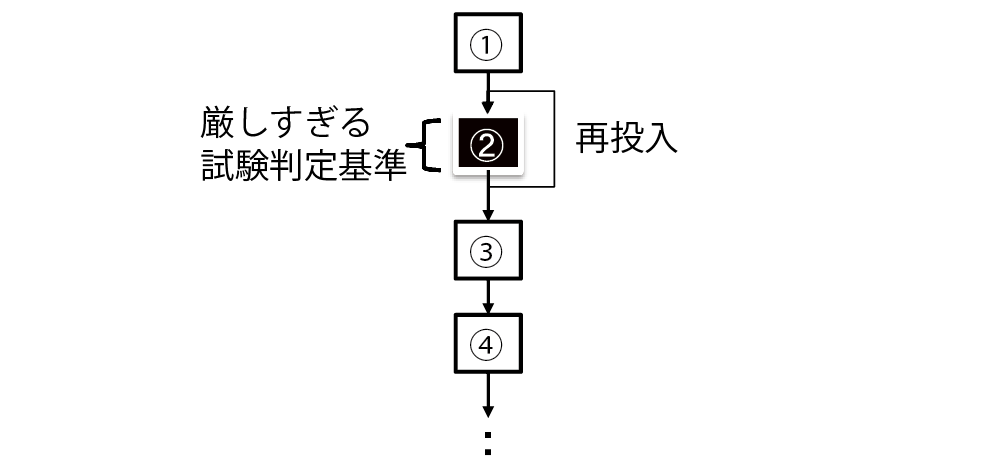
試験判定基準が厳しすぎる場合は,本来合格と判断しても後の工程に影響を及ぼさない製品も不合格と判断してしまう.これを過剰な排除と呼んでいる.なお,一般的には試験判定基準は,不良品を次工程に流さないために,厳しく設定されることが多い.
試験判定基準が厳しい場合,再投入回数の増加による製造効率悪化や,製品廃棄の増加による歩留低下に繋がる.ほかにも,試験に合格するため,部品や材料には,高い品質が要求されるため,原価高にも繋がる.
図3は,工程2における試験項目の試験判定基準が厳しいため,再投入が多発する例である.
- 人手による試験判定基準調整の作業量
製造工場は多数のライン,工程で構成されている.そして,工程同士の組合せは多岐に渡り,試験項目・計測項目同士の組合せは膨大な数になる.そのため,ある試験項目における試験判定基準の変更による影響をすべて人手で確認して調整することは,非現実的である.
3.試験判定基準の最適化
筆者らは,試験判定基準の自動最適化を目的とした「試験判定基準最適化方式」を開発した.本方式は,計測・試験項目同士の相関関係と,既存の試験判定基準に基づく方式である.計測・試験項目間に相関がある場合,そのときの相関関係や試験判定基準を調査することで,製造データに基づいた試験判定基準が検討できる.
本方式は,計測・試験項目同士で相関がある場合,それを用いて試験判定基準が調整できる項目を推薦する.試験判定基準が強化可能な試験項目を推薦する「強化推薦機能」および,緩和可能な試験項目を推薦する「緩和推薦機能」の2機能で構成される.
計測・試験項目同士に相関が発生する想定ケースについて,部品同士を組み立てて製造する製品を例として説明する.前工程の部品溶接工程では,溶接時の部品温度や溶接時のずれ幅(溶接誤差)を測定している.中間の工程では,耐久試験として部品に電流を流し続け,温度や抵抗値を取得している.最終工程では耐圧試験を実施している.
最終工程は,前工程および中間工程と密接な相関関係がある.溶接誤差が大きいと部品同士の接触が悪くなり,抵抗値が低くなる.また,負荷試験では,抵抗値が低いため想定より大きな電流が流れる.そのため,最終的には製品は不合格と判定される.3.1 強化推薦機能
強化推薦機能は,後工程で不合格となる製品の前落としを目的とした機能である.試験判定基準の強化が推奨されるすべての試験項目・計測項目と,強化後の試験判定基準を出力する.本機能では,工程同士,試験・計測項目同士すべての組合せより,強い相関関係がある組合せを抽出して,試験判定基準の強化や,新たな基準の設定が推奨される項目を推薦する.
図4に,強化推薦機能の概要を示す.この図は,ある1つの製品について,横軸・縦軸をそれぞれ前工程・後工程の試験項目における測定値としてプロットした散布図である.また,斜めの直線は,前工程・後工程間の測定値をもとに算出した回帰直線である.図4の例では,両試験項目とも,試験判定基準として上限値・下限値が設定されている(図中の4本の破線).
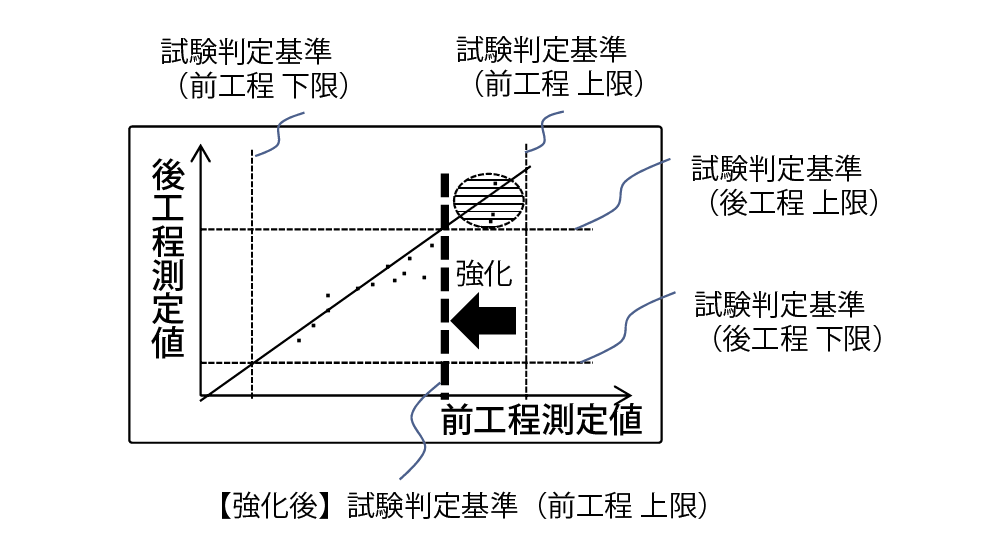
図4の例では,前工程における測定値が,前工程試験判定基準の上限値に近い場合で,後工程にて不合格になっていることが読み取れる(図中網掛け部分).ここで,前工程の試験判定基準の上限値を,回帰直線と後工程の試験判定基準の交点まで下げて強化することで,後工程で不合格となる製品を前落としできると考えられる.
3.2 緩和推薦機能
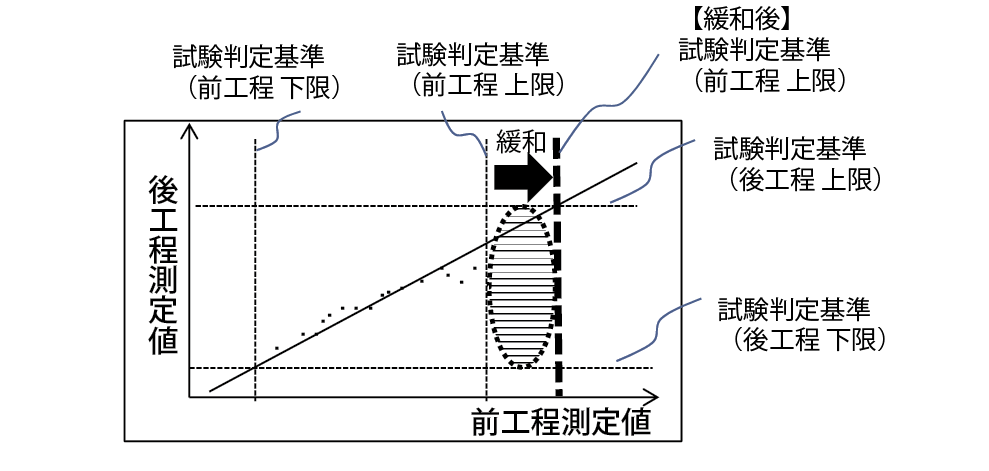
緩和推薦機能は,製品の過剰な排除の防止を目的とした機能である.ある工程における試験判定基準を緩和しても,その工程よりも後の工程へ影響を及ぼさない試験項目と,緩和後の試験判定基準を出力する.
既存の試験判定基準および回帰式に基づく手順は,強化推薦機能と同様である.試験判定基準の緩和によって,後工程で不合格の増加や,不良品多発などの不具合が発生してしまっては本末転倒となる.そのため,本機能は前工程の試験項目と相関のある全ての試験項目を評価した上で,後工程で不具合が発生しない試験項目がある場合のみ,結果を出力する.
図5に概要を示す.網掛け部分が従来前工程で不合格となっていたが,試験判定基準を緩和することで合格となり,なおかつ後の工程でも不合格とならない製品である.
4.実証実験と考察
本章では,実際の製造データを用いて,試験判定基準最適化方式を実証した結果を紹介する.
4.1 実証環境
試験判定基準最適化方式の実証にあたり,3つの機能を持つ実証システムを構築した(図6).1つ目は,工場より取得した製造データを,本方式で取り扱える形へ変換する前処理機能である.2つ目は,第3章に述べた強化推薦機能,緩和推薦機能を実行する試験判定基準最適化機能である.3つ目は,推薦された結果を図表としてまとめるレポート作成機能である.
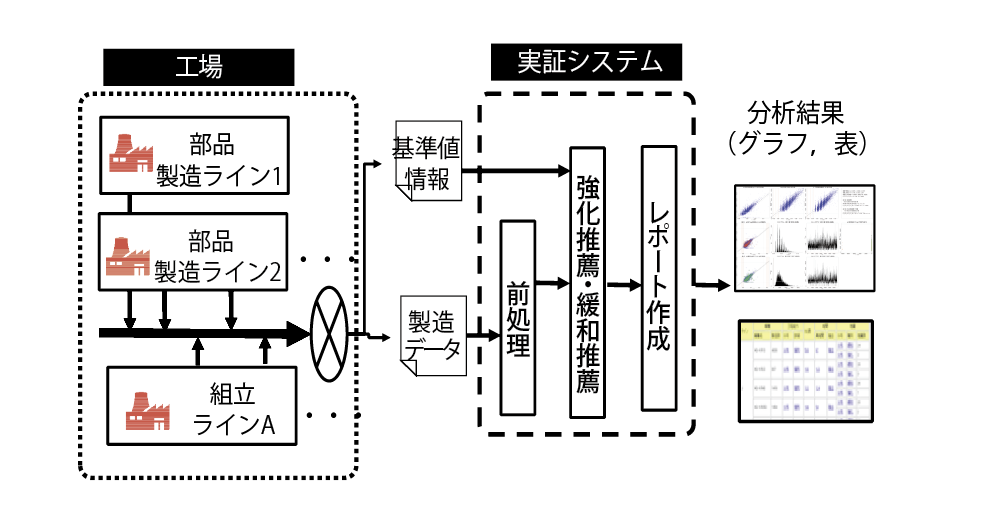
本実証実験は,部品組立工場で実施した.この工場は,数個のラインと,数十個の工程,数百個の計測項目と試験項目で構成される.この工場で製造される機種の中でも代表的な機種を実証実験対象として,数万台分の製造データを用いた.
4.2 実証結果
本節では,実証実験の結果について述べる.
今回用いた数万台分の製造データのうち,強い相関関係(0.6以上)となる組は数百件あり,強化推薦された試験項目が5件,強化推薦された試験項目や計測項目は0件であった.
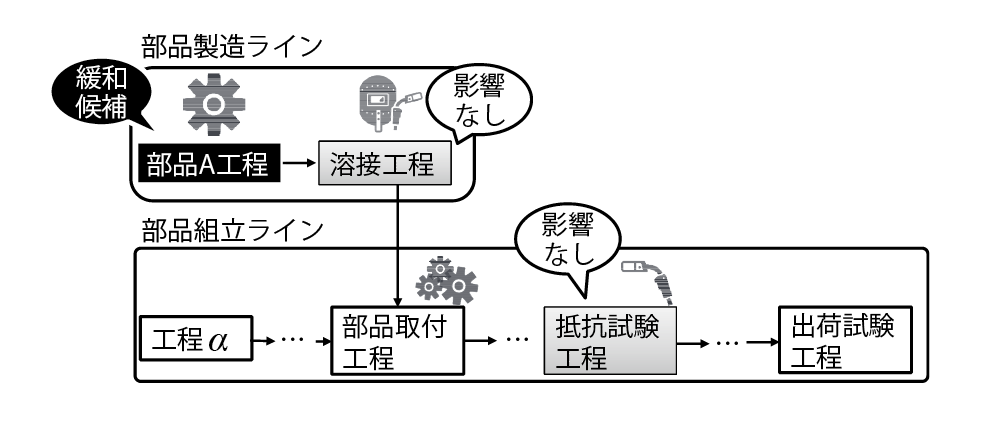
緩和推薦された結果5件のうち,4件については後に述べるヒアリング結果により,緩和不可能であるため割愛する.残る1件の緩和候補は,部品製造ラインに含まれる部品工程の部品高さに関する試験である.この部品高さ試験は,同じ部品製造ラインの後工程にあたる部品溶接工程の試験および,別のラインの抵抗試験工程の試験と相関関係があることが抽出された.そして,部品高さの試験判定基準(下限値)は,3%緩和したとしても,相関のある後の工程にて試験不合格が増加しないため,緩和候補として推薦された(図7).
実証結果について,現場担当者と製品設計開発者にヒアリングして得られたコメントは3つあった.
まず,緩和候補として挙がった5件のうち4件は,製品仕様に関する項目であるため,変更は不可能である.
次に,残りの1件の緩和候補である部品高さの試験判定基準は,緩和した場合,部品を従来よりも緩い公差で製造できる見込みがある.現状よりも緩い公差で製造することで,部品の原価を低減できる可能性がある.しかし,部品高さの緩和はライン,工程,装置の仕様変更が必要であるため,即時適用は難しい.
3つ目は,現状では製造データが取得されていない項目との関係性について指摘があった.現状では目視試験が行われており,製造データが取得されていない項目がある.緩和候補として挙がった部品高さは,この目視試験と関連性が高い可能性がある.そのため,基準の緩和が,その目視試験へ与える影響についても別途確認が必要となる.
4.3 考察
筆者らが開発した手法は,以下2点の理由により,試験判定基準の課題解決に有効である見込を得た.
1つ目は,試験判定基準変更の裁量を持つ品質保証担当者へ提案する情報として活用できる点である.試験判定基準は,不良品の流出防止のために厳しく設定することはあった.しかし,緩和については,ほかの工程へ与える影響が不明であるため困難であった.開発した手法は,試験判定基準の強化・緩和による影響を網羅的に調べることができるため,有効である.
2つ目は,設計・開発者の開発業務へフィードバックできる点である.本手法による推薦結果を開発者らの現場知見と照合することで,製品開発のフェーズへとフィードバックできる.フィードバックを重ねることで,設計段階の施策や検証をシミュレートできるようになるため,設計効率の向上や,手戻り削減に繋がる.
今回の製造データからは,試験判定基準強化によって不合格の前落としが期待できる試験項目は発見できなかった.これは,この工場では基準が厳格に管理されていることを定量的に示したと言える.また,試験の不合格については,製造データ間の相関とは無関係で発生する傾向があることも確認した.品質の厳格化のため,相関と無関係で発生する不合格の原因の特定が必要となる.
5.得られた知見
5.1 データ前処理における課題
本実証実験で,最も時間を要した作業工程はデータの前処理であった.本節では,実際のデータを用いた試行錯誤や,製造現場とのヒアリングにより抽出した課題を紹介する.
データの前処理は非常に重要であることはよく知られている.データ分析の標準的なフレームワークであるCRISP-DM(Cross Industry Standard Process for Data Mining)では,データ分析のフローを「ビジネス理解」,「データ理解」,「データ準備」,「モデリング」,「評価」の6ステップで定義している[8].データが分析をするために十分であるか検討して,データの特性を把握する「データ理解」および,実際に分析するためにデータを加工する「データ準備」が,データ分析における工数の8割以上を占めるとされており,大変重要な作業工程である[9][10].
以下に,製造データより,分析用データとして特定製品の製造データを抽出する際の課題を2点述べる.
1点目の課題は,ラインや工程ごとにデータ形式が異なる点である.製品や試験項目を識別するためのデータ項目名や,試験判定基準の形式が異なる場合がある.その場合,一括して分析機能で扱うためには形式の差異を抽出して,形式を統一する必要があった.このように,分析前のデータ形式の調査や統一が必要となる.
2点目の課題は,正常なデータの抽出である.データを抽出して集計する際,抽出したデータが意図通りの値であるかの吟味が必要である.たとえばデータの未測定・未入力といったエラー発生時は,欠損値や外れ値が測定値として記録される場合がある.これらの値は,本来の意図と異なる値である.
特に,多変量解析などの統計的手法は,欠損値や外れ値はないことが前提となっている.相関分析や分散・偏差に代表される統計的手法は,外れ値の影響を大きく受ける.意図通りの集計結果を得るためには,欠損値や外れ値の扱いを十分に検討する必要がある.
以降の節にて,今回の実証実験で特に注意して実施した前処理内容と知見を紹介する.
5.2 工場情報の列挙と一元管理
製造データからの分析用のデータ抽出および,その作業量削減のために,工場情報を列挙して一元管理できるようにした.本節では,試験判定基準の特徴と,工場情報の列挙および一元管理内容について述べる.
5.2.1 試験判定基準の特徴
試験判定基準には,扱いを変える必要があるケースが3種類ある.これをここでは「特徴」と呼ぶ.
1つ目は,試験判定基準の範囲が異なることである.これは3通りあり,上限値と下限値の両方が設定されている試験と,上限値のみの試験,もしくは下限値のみ設定されている試験がある.また,同じ試験項目であっても,製品によって,上限値や下限値は異なる.
2つ目は,試験判定結果の値の解釈方法である.工程や試験によって,試験結果の出力値の意味が異なる場合がある.たとえば,ある工程では合格のときは0を出力して,不合格のときは1を出力する.しかし別の工程では,合格のときは同様に0を出力するが,測定値が上限値を超過したため不合格となったときは1を,下限値未満で不合格となったときは−1を出力する.
3つ目は,試験項目が取り扱う測定値ごとの型である.アナログ値と,ディジタル値,文字列の3通りアナログ値と上下限値に基づいて合否を判定する場合と,ON/OFFや0/1のようにディジタル値,もしくは文字で合否を判定する場合がある.
5.2.2 工場情報の列挙
筆者らが開発した手法は,製造データと工程の前後関係に基づき,最適な試験判定基準を推薦するものである.ラインや工程によって,5.2.1項に述べた試験判定基準の特徴が異なる場合,測定値や試験判定結果を人手で確認した上で,分析用のデータを抽出する必要があり,作業量が非常に多くなる.
そこで,製造データ抽出の作業量削減を目的に,以下2点を列挙し,試験項目における差異を一元管理した.
1つ目は,試験項目ごとの特徴と試験判定基準である.各試験項目は,どのような値を,どのような試験判定基準の範囲で判定するか.また,試験判定結果はどのような出力であるかを列挙した.そして,製品ごとに各試験判定基準の範囲を整理した.
2つ目は,ラインや工程の前後関係である.今回開発した手法は,ラインや工程の前後関係が重要となるため,現場では周知の知見であるがラインや工程の接続関係について列挙した.
5.2.3 列挙による効果
試験項目ごとの特徴と試験判定基準を列挙することで,既存の試験判定基準の抽出および,分析に用いるアナログデータ抽出が容易になり,作業量を削減できた.今回の実験では,手作業による抽出と比較して,作業量を約7割削減できた.また,ラインや工程の前後関係を列挙することで,工程の前後関係をプログラムで判別することができた.
本節で述べた,試験ごとの特徴の抽出は,試行錯誤と現場知見のヒアリングなしではできなかった.
工場における製造データ分析の際は,ラインや工程,試験や機種ごとの特徴を列挙して一元管理することで,データ抽出の作業量が削減され,より効率的にデータが活用できると考えられる.
5.3 測定エラー時の処理
本検証の過程で製造データのエラー値の処理を行った.本節では,エラー値例とその発生原因,実施した対応について述べる.
5.3.1 エラー値の発生原因
試験不合格時の正常に取得された測定値は,不合格原因を推定するために有効な情報である.たとえば抵抗値を測る試験の場合,製品に付着したゴミにより,ほかの大多数の傾向よりも抵抗値が低く測定されることがある.抵抗値が低く,不合格の場合,製品の清掃を推奨するといった対策に繋げることができる.
一方で,データ未測定や未入力など,測定失敗時も,測定値として何らかの値が取得されてしまうことがある.その状況で取得された値は,上記の不合格傾向を表す有効な値ではなく,分析に適さないノイズとなる.
たとえば,抵抗値の試験にて,製品が正常に試験装置へ設置されない状態で試験装置による計測が行われる場合がある.このとき,製品の抵抗値は測定できないが,測定失敗の「エラー値」として,999,999,999が測定値として取得される.
このようなエラー値は装置やその装置メーカによって定義が異なる.例として挙げた999,999,999のほか,“ERR”といった文字データや,欠損を示す“NA”, “NULL”,または装置で取り扱える最大・最小値や, 0,−1といった定数値が取得される場合がある.
5.3.2 エラー値の除外
エラー値は分析の前に除外する必要がある.
理想的な除外方法は,計測項目や試験項目ごとのエラー値を列挙して一元管理して,計測値がエラー値であった場合は除外する仕組みをつくることである.だが,機器は多岐にわたっており,すべての機器を調査・ヒアリングする作業量が多いため,すべての機器のエラー値を抽出することができなかった.
そこで,今回は統計的な手法で,合格品の測定値の傾向を抽出した.エラー値への対応を行うことで,製造データから,分析に適したデータを抽出することができた.そして,製造データに相関分析をはじめとする統計的な手法が適用できた.
製造データを取得するシステムを構築する際は,機器ごとのエラー値を統一するなど,エラー値の管理を厳密化していくことで,誰でも製造データの抽出および活用が可能になると考えられる.
5.4 知見に基づくチェックルールの定義
工場の合否判定の基本的なルールは,2.3節に述べた.試験判定基準を満たさない製品は不合格となり,次の工程には進まず,合格品のみが次の工程に進む.だが,分析を進めるうちに,測定値は試験判定基準を満たしていないが,判定結果が合格となっている工場のルールに従わないデータを発見した.本節では,ルールを満たさないデータとその対策について述べる.
5.4.1 ルールを満たさないデータ
検証で扱ったデータの中に,測定値が,試験判定基準の範囲外であるにもかかわらず合格となっている製品があった.調査により,製品の合否判定結果と,測定値との不整合が原因であることが判明した.不整合発生の一例を以下に示す.
まず,試験で不合格となった製品は,一度工程から除外され,人手で手直しされる.
次に,手直しした製品を再度工程へ投入して,試験する.この再投入の試験が人手で実施されたとき,測定値がシステムへと反映されないことがある.測定値がシステムに反映されなかった場合,再投入によって合格した製品であっても,システムには過去の不合格時の情報しか残らない.
最後に,手直しされた製品を次の工程へと投入する.このとき,システムに再試験の結果が反映されておらず,製品はシステム上,不合格判定のままである.そこで,人手でシステムを操作して,該当製品の合否判定結果のみを変更する.
このような例外的な現場オペレーションによって発生する,ルールを満たさないケースを発見した.
5.4.2 チェックルールの定義
5.4.1項に述べたルールを満たさない測定値は,5.3節に述べた通り,分析には適さないデータとなる.そのため,除外もしくは補間が必要となる.
今回は,このような例外的なデータを除外するため,試験判定結果が合格かつ,測定値が試験判定基準の範囲何である製品のみを合格製品として抽出するよう,「チェックルール」を導入した.5.3節に述べたエラー値除外と,このチェックルールにより,分析に必要となるデータを抽出できた.
だが,工場ごとに現場オペレーションなどの知見を逐一抽出して,製造データと照合した上で,チェックルールを定義していては前処理の作業量が多くなる.
最適ではないが妥当なやり方の1つとして,さまざまな工場に対応できる分析用データの標準形を設計し,その標準形に基づいてチェックルールを設計することが考えられる.このように,標準形と,チェックルールの設計をすることで,データ活用方式を共通化できる.そして,データの活用方式をさまざまな工場へ展開できると考えられる.
5.5 今後の課題
今回の分析により,以下3点の課題を確認した.
1点目は分析用データの標準化である.データ分析では,データ前処理の作業量が非常に多い.既存の工場システムや,データ収集の仕組みを逐一分析に適した形へと変換して対応していては,時間とコストを要してしまう.そのため,ヒアリングに基づいて個々に前処理方式を検討することは現実的ではない.データ活用方式を,さまざまな工場へ横展開していくためには,分析用データの標準形の検討が必要となる.
2点目はセンシングの強化である.今回,緩和が推薦された試験項目は目視で実施しており,データがない試験と密接な関係があることが分かった.データの取得に要するコストとのトレードオフとなるが,試験項目と関係がある製造データの取得を強化することで,より分析精度が向上すると考えられる.
3点目は,相関とは無関係に発生する試験不合格への対応である.今回開発した手法は,工程同士の相関に基づく手法である.一方,不合格は相関関係と無関係に発生することもある.品質強化を図る上で,この不合格原因の特定と対策が重要となる.筆者らは現在,分析で用いるデータの種類を増やした上で,不合格原因を特定する手法を検討中である.
6.おわりに
本稿では,部品組立工場で取得した製造データを活用して,最適な試験判定基準を推薦する手法を紹介した.手法の実践例として,製造データを分析した結果を紹介し,製造現場にとって有効となる結果が得られたことを述べた.
実証実験を通じて得られた知見として,データ抽出に要する作業量を削減するため工場情報の列挙や.エラー値除去,チェックルールの定義について述べた.
工場データは,製造装置の特性,製造現場特有のオペレーション,製品によって特性が大きく異なるため,データを正確に理解することが重要である.また,分析結果は,現場では暗黙的に知られていることや,周知の事実である場合が多い.そのため,製造データの分析においても,CRISP-DMサイクルのように,データ理解,分析試行,フィードバックのサイクルを早く回し,関係者と分析状況を共有していくことが重要である.このサイクルを回すためには,従来のITを使った業務改善の取り組みと同様に,現場とIT部門との連携・理解が重要である.
本稿が,工場の製造データ分析・活用を検討されている方々の一助になれば幸いである.
参考文献
- 1) Industrial Internet Consortium : http://www.iiconsortium.org (accessed 2017-04-25)
- 2) Henning, K., Wahlster, W. and Helbig, J. : Recommendations for Implementing the Strategic Initiative Industrie 4.0,Acatech (2013).
- 3) IVI公開シンポジウム 2017 -Spring- : http://iv-i.org/wp/2017/04/20/symposium170309/ (accessed 2017-04-25)
- 4) 総務省:平成27年度版 情報通信白書,ICT化の進展がもたらす経済構造の変化,pp.295-298 (2015).
- 5) 総務省:平成28年度版 情報通信白書,国際的なIoTの進展状況,pp.113-115 (2016).
- 6) 永田 靖:統計的品質管理,朝倉書店(2009年6月).
- 7) 飯塚悦功:現代品質管理総論,朝倉書店(2009年11月).
- 8) Shearer, C. : The Crisp-dm Model : The New Blueprint for Data Mining,Journal of Data Warehousing, pp.13-22 (2000).
- 9) 佐藤洋行:データサイエンティスト育成読本,技術評論社(2013).
- 10) 福島真太郎:シリーズUseful R データ分析プロセス,共立出版(株)(2015).
2013年群馬大学大学院工学研究科情報工学専攻修士課程修了.同年三菱電機(株)入社.情報技術総合研究所勤務.データ分析技術の研究開発に従事.
平井 規郎(正会員)Hirai.Norio@dx.MitsubishiElectric.co.jp1991年東京工業大学大学院理工学研究科情報科学専攻課程修了.同年三菱電機(株)入社.情報技術総合研究所勤務.データ検索,データ分析,データベース技術の研究開発に従事.データベース学会会員.
生方 康友(非会員)Ubukata.Yasutomo@bc.MitsubishiElectric.co.jp2012年東京理科大学大学院理工学研究科機械工学専攻修士課程修了.同年三菱電機(株)入社.
編集担当:北村操代(三菱電機(株) )