SINET広域データ収集基盤を用いたオンラインビデオ処理実証実験
Demonstration of an Online Video Processing Framework using the SINET Wide-area Data Collection Infrastructure
1. はじめに
ビデオデータのオンライン解析は,自動運転における物体認識や防犯カメラでの異常検知等の用途でその需要が高まっている.高度なオンライン解析処理を行うには,センサで取得したビデオデータを広域網を用いてクラウドに収集し,クラウドの高性能な計算資源を用いて大量のビデオデータの解析処理を行い,その結果を利用者またはセンサ側に送信する必要がある.しかしながら,このような処理では以下のような技術的課題がある.
- (1)センサとクラウド間のモバイル網の帯域と安全性
- (2)大量データの収集性能
- (3)クラウドでのオンラインビデオ解析処理の性能
( 1 )は,モバイル網を用いることで各種センサへの接続が容易になるが,既存の4G/LTE回線を介して大量のセンサから連続的に生成されるデータをクラウドの計算資源に送信する場合,モバイル網の帯域を考慮したIoTアプリケーション設計が必要とされる.また,サイバー攻撃等からセンサやクラウド計算資源を守るために外部ネットワークから隔離されていることが望ましいが,特にモバイル網ではそのような隔離は難しい.( 2 )は,データサイズの小さい大量のセンサデータをクラウドのストレージに直接書き込むには,オブジェクトストレージの書き込み性能やHTTPプロトコルのオーバヘッドなどが課題となる.IoT(Internet of Things)通信向けにMQTT(Message Queue Telemetry Transport)[1]のような軽量プロトコルを用いたメッセージング基盤が複数開発されているが,個々のアプリケーションの要件を満たすのに必要な構成などが明らかでない.( 3 )は,オンライン処理をするにはストリームデータの到着速度とビデオ解析処理速度とのバランスを取る必要があるが,その性能要件も明らかでない.特に,広帯域,低遅延の第5世代移動通信システム「5G」の利用が可能になると,性能ボトルネックはクラウドでの解析処理へと移行するため,その検証が必要不可欠である.
本研究では,SINET広域データ収集基盤[2]を用いたオンラインビデオ処理機構のプロトタイプシステムを構築して実証実験を行うとともに予備評価を行い,オンライン処理システムを構成するメッセージング基盤および分散ストリーム処理基盤の性能特性を示す[3], [4].画質およびフレームレートを調整可能なシステムを構築するとともに,SINET広域データ収集基盤を用いてモバイル網を含むネットワーク全体の隔離を実現することで,( 1 )の課題を解決する.また,予備評価により,( 2 ),( 3 )の課題について明らかにする.
SINET広域データ収集基盤は,国立情報学研究所(NII)が提供する学術情報ネットワークSINETへの新たなアクセス環境として,モバイル網をSINETの足回りとして活用した広域的な基盤であり,2018年度から実証実験を開始している.提案するプロトタイプシステムでは,本モバイル網とSINET L2 VPN(Virtual Private Network)の閉域網を用いて,安全かつ広帯域なネットワークを介してオンプレミス環境および商用クラウド環境にデータを収集する.また,オンプレミスおよびクラウドでメッセージング基盤の構築,オブジェクトストレージとの連携,クラウドのGPUノードを用いたオンライン処理が実現可能であることを示す.
プロトタイプシステムのメッセージング基盤には,既発表研究[5]で高スループットで画像データの収集ができることを確認しているApache Kafka [6], [7], [8]を採用した.また,提案するオンラインビデオ処理機構のアプリケーションとして,収集したストリームデータからオブジェクト抽出するライブラリYOLO v3 [9], [10]のPyTorch実装[11]と,人のキーポイント抽出ライブラリOpenPose [12], [13], [14], [15], [16]を用いる.これらの画像処理ライブラリでオンライン処理するプログラムを開発し,オンラインで処理できることを示す.
プロトタイプシステムの構築には,「学認クラウドオンデマンド構築サービス」[17], [18]を用いた.これにより,クラウド上に短時間でアプリケーション環境を構築することができる.また,構築および実証実験実施の際に用いたプログラムはオープンソースとして公開した[19].
予備評価では,オンラインIoTアプリケーションを構築するための設計指針を得ることを目的とし,オブジェクトストレージとメッセージング基盤のIO性能と,既存分散ストリーム処理基盤を用いた処理性能を調査する.オブジェクトストレージの評価では,オンプレミスおよびクラウドのオブジェクトストレージの基本性能を比較する.メッセージング基盤の評価では,KafkaとMQTTブローカ実装の一つであるEclipse Mosquitto [20], [21]の性能を調査した.また,既存分散ストリーム処理基盤の評価として,Apache Flink [22](Flink)とApache Storm [23](Storm)を用いたクラスタ環境をそれぞれ構築し,そのうえでセンサデータ量と処理遅延とスループットの関係を明らかにする.分散ストリーム処理基盤では,Flink,Stormの他,Spark Streaming(Spark)[24]も一般に広く利用されているが,Sparkは遅延やスケーラビリティの点でFlinkやStormに劣ることが示されているため[25], [26],本研究ではFlinkとSparkを用いる.
実験から,大量のセンサデータを扱うにはオブジェクトストレージでは不十分でメッセージング基盤を活用することが望ましいこと,MQTTベースのMosquittoはクライアント用のライブラリが充実しているという利点もあるが,大量データのデータ収集にはKafkaが優位であること,IoTアプリケーションの要件に合わせてソフトウェア構成を設計する必要があることを示す.また,分散ストリーム処理基盤の評価ではFlink,Stormいずれのミドルウェアも多少のオーバヘッドがあるものの低遅延,高スループットで処理できることを明らかにする.
以降の本稿の構成は以下のとおりである.2章では,SINET広域データ収集基盤を用いた実証実験の概要を述べるとともに,実験で用いたプロトタイプシステムの構成と実験環境の詳細について述べる.3章では,オンラインIoTアプリケーションを構築するための設計指針を得ることを目的とし,オブジェクトストレージとメッセージング基盤のIO性能と,既存分散ストリーム処理基盤を用いた処理性能を示す.4章では関連研究,5章ではまとめと今後に課題について述べる.
2. オンラインビデオ処理機構プロトタイプシステムの構築
SINET広域データ収集基盤を用いたオンラインビデオ処理機構のプロトタイプシステムを構築し,2019年4月に開催された人工知能の活用をテーマとしたイベントAI/SUM [27]のショーケースで実証実験を行った.以降で,実証実験の概要について述べた後,プロトタイプシステムのソフトウェア構成と構築した実証実験環境の詳細について述べる.
2.1 SINETモバイル網を用いた実証実験
NIIでは,学術情報ネットワークSINET5とモバイル通信を直結したサービス「SINET広域データ収集基盤」の実証実験を開始した.SINET広域データ収集基盤では,大学等のSINET加入機関の研究者がSINET接続用のSIMを用意してセンサ等に装着することで,それらが送信するデータをSINETに接続された計算環境で収集,解析することができる.モバイル通信を活用することで,これまでSINETが接続できなかった場所での研究データの収集やIoT関連研究が可能になる.
図1に実証実験の概要を示す.実験では,センサ端末のカメラで取得した動画像から複数の静止画を生成し,その静止画を順次SINETモバイル網経由でクラウド上のメッセージング基盤に送信・収集し,そのオンライン画像解析処理ができることを示した.ここで,センサ端末,クラウド上のメッセージング基盤,オンライン画像解析処理を行うGPUノードはすべてSINETのVPNを用いて安全に接続することができている.
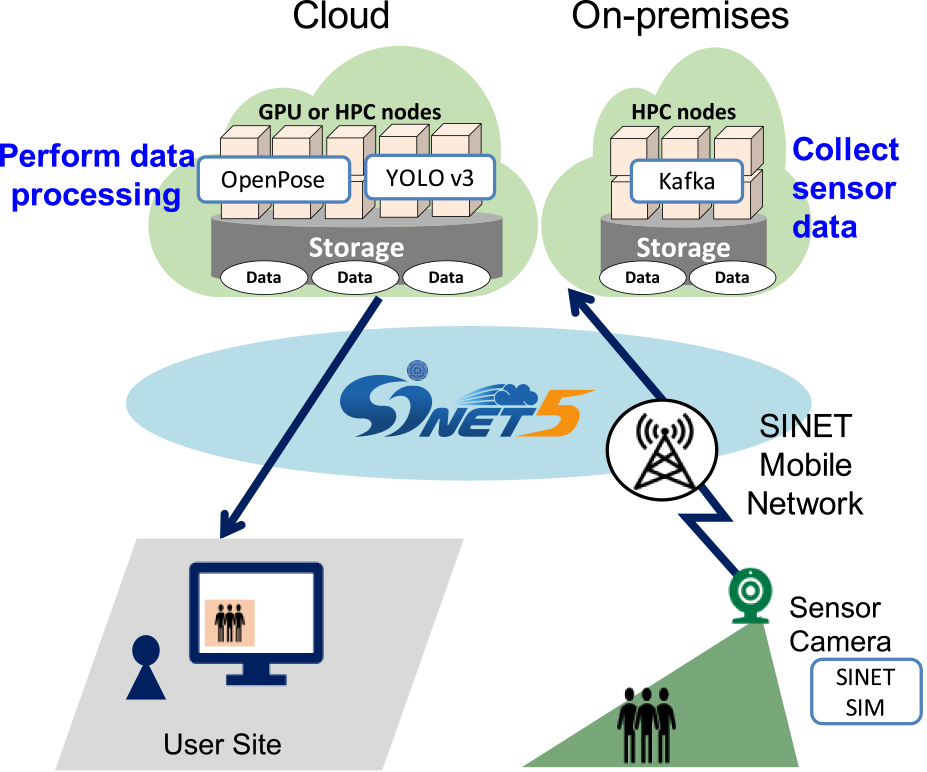
Fig. 1 An overview of an online video processing demonstration over the SINET mobile network.
図2に実証実験実施時の利用者端末のキャプチャ画面を示す.図2の右側上下に並んでいる画像は,センサ端末のカメラで取得した動画がクラウド上のメッセージング基盤を介して利用者端末にストリーム配信された結果が表示されている.右側上には屋外を移動しているセンサ端末のカメラ画像,右側下にはAI/SUM展示会場に設定されたセンサ端末のカメラ画像が表示されている.また,左側上下に並んでいる画像は,処理前画像をメッセージング基盤から受け取り,クラウドで何らかの処理をした処理後画像を,メッセージング基盤を介して配信して利用者端末で出力された結果となっている.ここで,左側上の画像はYOLO v3を用いてオブジェクト抽出を行った結果,左側下の画像はOpenPoseを用いて人のキーポイントを抽出した結果が表示されている.
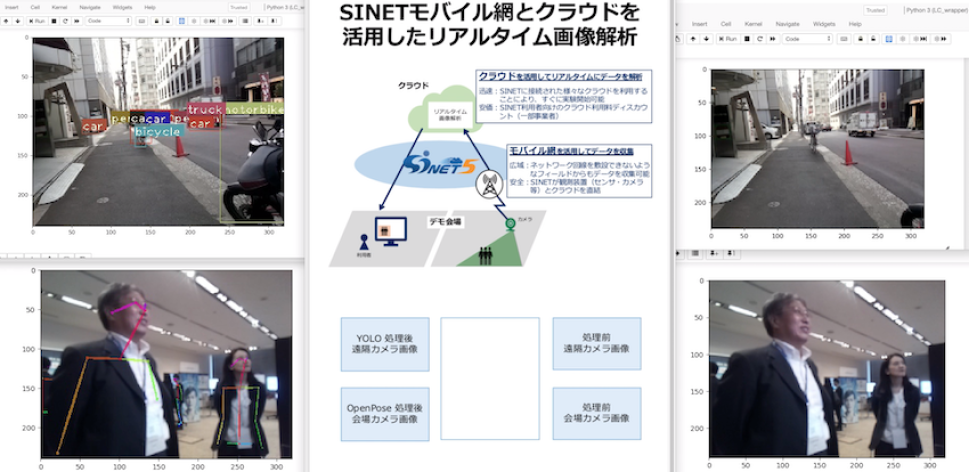
Fig. 2 A snapshot of the online video processing demonstration.
モバイル網を利用して画像を送信する場合,その実効通信帯域が課題となる.センサ端末のカメラで取得した動画から切り出した静止画をそのまま送ると画像サイズが大きく十分な枚数の画像が送れなくなってしまうため,センサ端末で320×240画素,64 KB弱の静止画に変換してから送信するようにした.実効通信帯域は電波状況等により変化するが,実験では6 fps程度のフレームレートとなっていた.クラウドでは,YOLO v3およびOpenPoseの各処理に対してそれぞれGPUノードを1台ずつ用いた.OpenPoseでは,6 fpsのデータに対するオンライン処理ができることを確認した.一方,YOLO v3はOpenPoseより解析処理の負荷が高いため,画像数を半分程度に間引きながらオンライン処理を行った.
2.2 プロトタイプシステムのソフトウェア構成
オンラインビデオ処理実験で用いたプロトタイプシステムの概要を図3に示す.図3の右側にあるセンサ端末からSINETのモバイル網を経由して静止画のストリームデータをメッセージング基盤に送信する.メッセージング基盤に到着したデータは,オンプレミスおよびクラウドのオブジェクトストレージにも格納することができる.図3左上にあるオンラインアプリケーションプログラムでは,メッセージング基盤に到着したストリームデータを順次受け取り,静止画を処理してその結果をメッセージング基盤に送信する.図3左下のオフラインアプリケーションプログラムでは,適宜オブジェクトストレージに格納されたデータをまとめて取得してバッチ的に画像処理する.右下の利用者端末で,メッセージング基盤に格納された処理前および処理後の静止画ストリームデータを出力する.
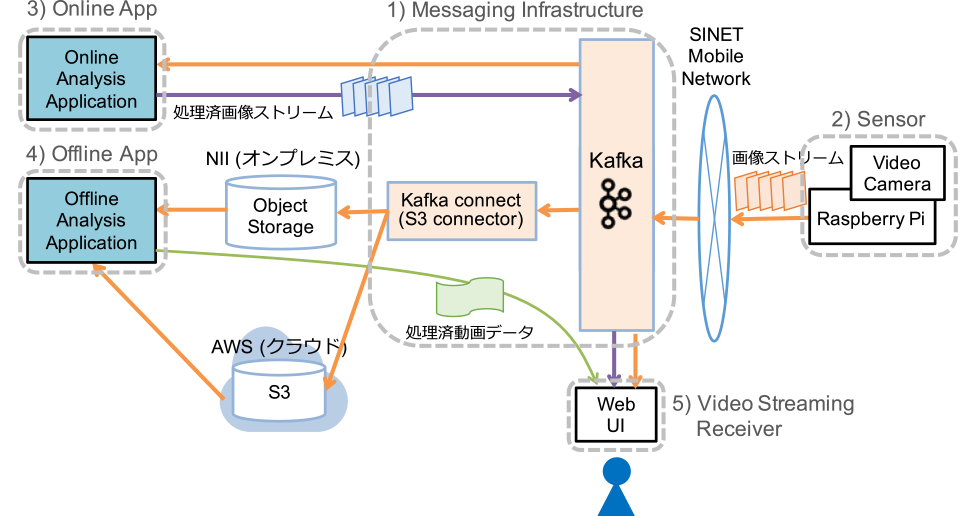
Fig. 3 Software configuration of the prototype system for online video processing.
本システムを構成するソフトウェアを,以下に示す.
- 1)メッセージング基盤プログラム
- 2)センサ用プログラム
- 3)オンラインアプリケーションプログラム
- 4)オフラインアプリケーションプログラム
- 5)ストリーム画像出力プログラム
各ソフトウェアについて以下で説明する.
1) メッセージング基盤プログラム
実験では,動画像は静止画のストリームデータとして配信・収集する.そのためのメッセージング基盤には,Apache Kafka(Kafka)を用いた.Kafkaは,Pub/Sub型非同期メッセージングモデルを採用するメッセージング基盤の一つであり,センサ等のProducerから送信されるメッセージをBrokerで一時的に収集,永続化し,データ処理プログラム等のConsumerに提供する.Brokerはクラスタ構成をとることで,スケールアウトが可能になっている.個々のストリームデータはTopicと呼ばれるカテゴリ単位で管理され,Topic名,値,タイムスタンプからなるレコードとして送信,格納される.
また,Kafka Connectと呼ばれるツールによりオブジェクトストレージやストリーム処理系,バッチシステム等との連携が可能になっている.プロトタイプシステムでは,Kafka Brokerで収集したストリームデータを,Amazon Web Services(AWS)のSimple Storage Service(S3)およびNIIのオンプレミス環境のS3互換オブジェクトストレージにそれぞれ格納するため,それぞれの認証情報を設定したS3 Connectorを利用した.ただし,オブジェクトストレージにPOSIXファイルシステムのパス名をマッピングする場合,同じフォルダ内に多数のファイル(オブジェクト)を格納する形にすると,フォルダ内全ファイルの検索等の処理時間が非常に長くなってしまう.具体的には,パブリッククラウドのオブジェクトストレージでファイル数が1万を超えると一覧取得処理のみで5秒から10秒かかることが報告されている[28].データをどう利用するかあらかじめ想定し,データを格納するパスを設計しておく必要がある.
2) センサ用プログラム
センサ端末にはRaspberry Piとカメラモジュールを用い,USB接続したモバイルルータを用いてSINET VPN経由でKafka Brokerに静止画を繰り返し送信するようにした.センサ用プログラムは,KafkaのProducerとして動作する.カメラモジュールから320×240画素の静止画を取得し,Topic名を指定して静止画のバイナリデータを送信する.Producerでは,転送性能を高めるためにデフォルト設定では複数レコードをまとめて送信するようになっているが,プロトタイプシステムでは1枚ずつオンラインで画像処理ができることを示すため,1レコードずつ送信するようにした.また,利用したカメラモジュールでは1秒間に30フレームの画像を取得することができるが,モバイル網で30 fpsで転送することはできないため,センサ用プログラムで取得するフレーム数を調整できるようにした.さらに,モバイル網を利用する場合センサ端末のデフォルトMTU(Maximum Transmission Unit)サイズが適切であるか,注意する必要がある.我々が用いた環境では,RFC2923のPath MTU Discoveryブラックホール問題が発生してRaspberry PiからKafkaに対して正常に通信できなかったため,MTUサイズを手動で調整する必要があった.
プロトタイプシステムの動作確認を目的とし,動画ファイルやS3互換オブジェクトストレージに格納された複数の静止画を用いて,指定したフレームレートでBrokerにレコードを送信するProducerコードも用意した.これにより,センサ端末の用意ができていない状況でもオンラインビデオ処理の動作確認が可能となる.
3) オンラインアプリケーションプログラム
オンラインアプリケーションプログラムでは,YOLO v3のPyTorch実装とOpenPoseを用いてそれぞれGPUノード上で画像を処理した.各オンラインアプリケーションプログラムでは,KafkaのConsumerおよびProducerの機能を利用している.まず,Brokerから順次静止画を受け取ると,それぞれのライブラリを用いて処理する.処理結果のストレージへの格納と利用者端末での結果確認のため,別のTopic名を指定してBrokerに送信する.オンライン処理のため,本プログラムでも必要に応じて処理する静止画の枚数を調節している.
4) オフラインアプリケーションプログラム
本研究ではオンライン処理をターゲットとしているが,複数静止画をまとめて処理するオフラインアプリケーションプログラムも用意した.オフラインアプリケーションプログラムでは,S3互換ストレージに格納された複数の静止画をOpenPoseで処理するプログラムを開発した.S3に格納されたデータへのアクセスでは,goofys [29]を用いた.goofysはGoで実装されており,S3互換ストレージをファイルシステムとしてマウントすることができ,s3fsより高速なアクセスが可能となっている[29].goofys経由で指定された複数の静止画を読み出し,個々の静止画に対して3)同様に画像処理を行い,生成された複数の処理済み画像からを一つの動画を生成するようにした.
5) ストリーム画像出力プログラム
利用者端末では,処理前および処理後静止画のストリームデータを動画像として表示させるストリーム画像出力プログラムを用意した.ストリーム画像出力プログラムもまたKafka Consumerプログラムであり,Brokerから受け取ったデータを順次利用者端末に出力する.本プログラムは,ウェブインタフェースで文書やコードを記述,実行できるJupyter Notebook [30]で実装し,表示したいTopicや表示レートなどがその場で適宜変更できるようにした.
2.3 実証実験環境構築とプログラムの公開
図4に実証実験環境を示す.実験では,SINETのL2 VPNでSINETモバイル網,VCP東京サイト,NII千葉サイト,AWS東京リージョンを接続し,閉域網を構築している.図中のセグメント1から4は,閉域網内のネットワークセグメントを表しており,すべてプライベートアドレスが設定されている.VCP東京サイトの仮想ルータを用いて,これらのネットワークのルーティング設定を行った.今回利用した仮想ルータは,「学認クラウドオンデマンド構築サービス」で提供しているものを利用した.
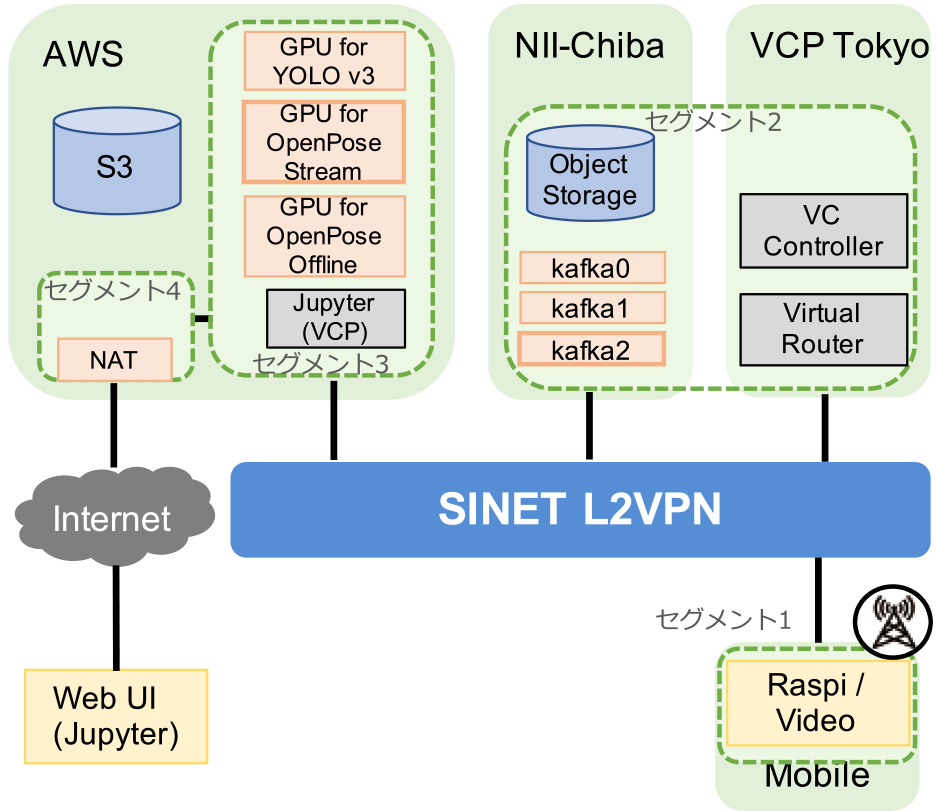
Fig. 4 Experimental settings for online video processing.
学認クラウドオンデマンド構築サービスは,SINET5とクラウドを活用したアプリケーション実行環境の構築を学術研究機関に対して支援することを目的として,2018年10月に運用を開始した.本サービスでは,仮想ルータの提供の他,NIIが開発したVCP(Virtual Cloud Provider)[31]と呼ばれる管理ソフトウェアを用いて様々なクラウドでの資源制御を容易にするとともに,研究・教育目的のアプリケーションの構築手順をJupyter Notebook形式で提供する.実証実験では,クラウドやオンプレミス環境に複数のプログラムを配備して環境構築する必要があるため,本サービスを用いた.
実証実験では,2.2節のソフトウェアを以下のように配備した.センサ端末のRaspberry Pi 2台には,3 Model B Rev 1.2,Debian v. 9.11を用い,SINETのSIMカードを利用してSINETモバイル網に接続させた.NII千葉サイトでは,3台クラスタ構成のKafka BrokerとS3互換オブジェクトストレージを配置した.AWSサイトでは,S3を利用するとともにGPUノードを必要に応じて確保してオンラインおよびオフラインアプリケーションプログラムを配備した.YOLO v3ではg3.8xlarge(GPU数2,VCPU数32,244 GiBメモリ,16 GiB GPUメモリ),OpenPoseではg3.4xlarge(GPU数1,VCPU数16,122 GiBメモリ,8 GiB GPUメモリ)を用いた.一方,操作性を考慮して利用者端末はパブリックインターネット経由で利用できるようにし,実験環境に対してはAWSのNATインスタンスを経由してアクセスするようにした.
実証実験環境の構築および実施の際に用いたプログラムは,「SINET広域データ収集基盤デモパッケージ」としてGitHubでオープンソースとして公開している[19].本パッケージは,クラウド資源の制御部分を除いて,学認クラウドオンデマンド構築サービスを利用しない場合にも活用できる.
3. 予備評価
オンラインIoTアプリケーションを構築するための設計指針を得ることを目的とし,有線環境でオブジェクトストレージとメッセージング基盤のIO性能と,既存分散ストリーム処理基盤を用いた処理性能を調査する.
3.1 予備評価の目的
一般に,オンラインIoTアプリケーションを構築するには,「センサデータの収集」,「解析処理」,「結果のフィードバック」までにかかる「応答時間」を各アプリケーションの要求される時間内に収める必要がある.オンラインIoTアプリケーションにおける「応答時間」の目安は,たとえば製造現場では,製造機械の制御では10ミリ秒以下であるのに対し,設備生産管理では数秒から数分と,個々の用途によって異なることが報告されている[32].また,それらで発生するデータサイズ,データ生成頻度,センサ数も大きく異なる.実験では,本稿で想定するソフトウェア構成において,どの程度のオンラインIoTアプリケーションが実現可能であるか明らかにする.
2章では,プロトタイプシステムによりSINET広域データ収集基盤の提供する4G/LTE回線を介してオンラインビデオ処理ができることを実証した.本実験では,「センサデータの収集」におけるモバイル網が性能ボトルネックとなっていたため,画質や転送レートを調整するとともにメッセージング基盤を用いてオンラインでの処理を実現した.一方で,センサデータの発生頻度が少ないIoTアプリケーションでは必ずしもメッセージング基盤を用いる必要がなく,オブジェクトストレージを利用して直接「センサデータの収集」を行い,より簡易な構成でアプリケーションを構築するほうが望ましいと考えられる.
また,複数のセンサデータを同時に扱う場合や広帯域,低遅延の第5世代移動通信システム「5G」の利用が可能になると,性能ボトルネックは「解析処理」へと移行する.既存分散ストリーム処理基盤の活用により処理をスケールアウトすることが期待できるが,様々なデータサイズや転送レートに対してどの程度の遅延,スループットで処理できるのか,明らかではない.
よって,本章ではオンラインIoTアプリケーションの設計指針を得るため,将来の広帯域,低遅延な環境を前提として有線環境で以下の評価実験を行う.「センサデータの収集」のための既存システムの性能特性を得るため,3.2節ではオブジェクトストレージのIO性能,3.3節ではメッセージング基盤のIO性能を調査,比較する.また,「解析処理」のための既存システムの性能特性を得るため,3.4節では既存分散ストリーム処理基盤の処理遅延,スループットを調査する.「結果のフィードバック」については,一般的に「センサデータの収集」よりータ量,発生頻度が少なくボトルネックになりにくいと考えられるため,本稿ではスコープ外とする.
3.2 オブジェクトストレージの性能
まず,オブジェクトストレージの評価ではAWS S3とNIIオンプレミス環境のHGST社製オブジェクトストレージ装置ActiveScale P100(以降,P100とする)のIO性能を調査する.P100は,システムノード3台,ストレージノード6台,864 TB(実効容量580 TB)構成であり,Inter-rackネットワーク帯域は40 Gbs,Intra-rackネットワーク帯域は10 Gbsとなっている.実験では,1台のシステムノードに対してIOアクセスを行う.
評価には,クラウドオブジェクトストレージのベンチマークソフトウェアの一つであるCOSBench [33]を用いた.アクセスパターンは,Writeを20%,Readを80%とし,読み書きしたデータのサイズは64 KiB,ベンチマークruntimeは60秒とした.リクエスタ用のノードは,オンプレミスでは表1に示す物理サーバ上に配備した8コア16 GiBメモリのVM 3台,AWSではvCPU 2コア,8 GiBメモリのm5.largeを3台用いた.オンプレミス環境では,リクエスタ用の物理サーバとP100が10 Gbpsで接続されている.AWS内では,S3のネットワークインタフェースは明らかでないが,各リクエスタVMは最大10 Gbpsの通信帯域となっている.
Table 1 Specification of the physical server for requesters in the NII on-premise environment.

図5,図6にWriteスループットを,図7,図8にはReadスループットを1秒あたりの総オペレーション数[op/s]と総バイト数[MB/s]でそれぞれ示す.横軸はリクエスタ数で,縦軸は総スループットを示している.青いバーの“NII->P100”はNIIのリクエスタからP100へ,橙色のバーの“AWS->S3”はAWS内部のリクエスタからS3へ,灰色のバーの“NII->S3”はNIIのリクエスタからS3へのアクセスとなっている.NII->P100とAWS->S3はクラウド内,NII->S3はクラウド間の通信となっており,後者は一部商用インターネット回線を利用している.
![Writeスループット[op/s]. Write throughput in op/s.](1-1-4-6.png)
Fig. 5 Write throughput in op/s.
![Writeスループット[MB/s]. Write throughput in MB/s.](1-1-4-7.png)
Fig. 6 Write throughput in MB/s.
![Readスループット[op/s]. Read throughput in op/s.](1-1-4-8.png)
Fig. 7 Read throughput in op/s.
![Readスループット[MB/s]. Read throughput in MB/s.](1-1-4-9.png)
Fig. 8 Read throughput in MB/s.
図5,図6の結果から,クラウド内でのWriteアクセスではリクエスタ数が増えるにつれて増加率は鈍るものの,スループット値が増加していくことが分かる.オンプレミスとクラウドでスループット値を比較すると,リクエスタ数が少ないときにはオンプレミスのほうが大きいが,リクエスタ数が多くなるとS3のほうが大きくなり,スケーラビリティの高さが確認できる.一方,クラウド間Writeアクセスではクラウド内アクセスより増加率は高いものの,スループット値は低く,リクエスタ数144のときにはベンチマークプログラムが正常に終了することができなかった.モバイル網を利用するような遅延が大きい環境では,一般に同一サイト内で測定されるWriteスループット値より低くなることを想定する必要があることが示唆された.
図7,図8のReadスループットの結果でも,クラウド内・クラウド間の実行結果はWriteスループット結果と同様の傾向がみられ,リクエスタ数144のときの実験結果は得られなかった.Readスループットは,Writeスループットの3倍程度から4倍近い性能を示していたが,1 Gbps程度であった.IoT環境のように小さいサイズのファイルを大量に扱う場合には,通信性能よりオブジェクトストレージ側の処理がボトルネックとなることが示された.
3.3 メッセージング基盤の性能
次に,メッセージング基盤として実証実験で用いたKafkaとMQTT実装の一つであるMosquittoの書き込み性能を比較する.Kafkaはクラスタ構成を取ることでスケールアウトが容易であり,永続化も可能である.Mosquittoは1ノード構成で利用し機能的にはKafkaに劣るものの,MQTTベースでAndroid等のセンサ側端末用クライアントライブラリが充実している,処理負荷が相対的に低いといった利点がある.実験では,Kafkaはv. 2.2.0,Mosquittoはv. 1.6.2を用いた.
メッセージング基盤の評価はAWS内で実施した.表2に評価環境を示す.Broker用ノードにはいずれもm5.2xlargeを利用し,Kafkaでは3台,Mosquittoでは1台用いた.リクエスタ用ノードには,m5.xlargeを1台ずつ用意した.ベンチマークプログラムには,KafkaではKafkaのパッケージで用意されているプログラムを利用し,MosquittoではMQTT-Bench [34]を用いた.
Table 2 Experimental settings for evaluation of messaging systems.

図9と図10にKafkaとMosquittoのWriteスループットを1秒あたりの総送信メッセージ数[msg/s]およびバイト数[MB/s]で示す.横軸は,実験の条件を<MQTT/Kafka>-<data size>-<qos/ack>と表記しており,“MQTT”はMosquittoの結果,“Kafka”はKafkaの結果を表す.二つめの数字は送信データサイズで,1 KiBと64 KiBの結果を比較する.三つめの数字はMQTTのQoSレベルであり,0は到着確認なし,1はKafkaのack相当のQoS1の結果を示している.Kafkaでは,ackの有無により1または0を表記している.青色,橙色,灰色の1,3,6は,リクエスタ数を表している.
![メッセージング基盤のWriteスループット[msg/s]. Write throughputs of messaging systems in msg/s.](1-1-4-11.png)
Fig. 9 Write throughputs of messaging systems in msg/s.
![メッセージング基盤のWriteスループット[MB/s]. Write throughputs of messaging systems in MB/s.](1-1-4-12.png)
Fig. 10 Write throughputs of messaging systems in MB/s.
図9,図10でKafkaとMosquittoの結果を比較すると,Kafkaのほうが高性能であることが分かる.QoSおよびackの有無の比較では,Kafkaではあまり性能劣化がみられないのに対し,Mosquittoでは大幅にスループットが低下していることが分かる.図10のMQTT-64K-0では高いスループット値を示しているが,MQTT-64K-1ではスループット値が大幅に低下しており,送信メッセージの多くがMosquittoのBrokerで受信できていないと考えられる.よって,Mosquittoを用いてセンサ端末で収集したデータを欠落することなくBrokerに収集したい場合には,少なくともQoS1の設定が必要であることが分かる.また,大量のデータを確実に収集する場合には,Kafkaのほうが有望であることが示された.
一方,図6の最大値と図10のQoS/ackありの条件でKafkaとMosquittoの最大値をそれぞれ比較すると,Kafkaで13.1倍,Mosquittoでも5.4倍のスループットとなっており,小規模データの大量処理ではメッセージング基盤の利用が非常に有効であることが明らかとなった.以上から,IoTのアプリケーションシナリオに応じて,適切なメッセージング基盤を選択することが望ましいと考えられる.
3.4 分散ストリーム処理基盤の予備評価
大量のストリームデータに対し複雑な分散処理を行うアプリケーション(アプリ)では,ノード間のデータ交換と同期,流量の変化に対するスケーリング,障害時のリトライといった課題に対処しなければならない.よって,既存分散ストリーム処理基盤ではプログラマが個々の処理とそれらの順序関係(パイプライン)を記述するだけで,スケーラブルな分散ストリーム処理アプリを迅速に開発・運用できる機能を提供する.本稿では,分散メッセージング基盤のKafkaと分散ストリーム処理基盤のFlinkおよびStormについてオンライン処理性能を検証するため,簡単なアプリによるストレステストを実施した.
3.4.1 評価方法
図11のように,メッセージをKafka→Flink→KafkaもしくはKafka→Storm→Kafkaという経路で流し,遅延とスループットを測定する.メッセージをKafkaに流し込むProducerは単体のPythonプログラムで,送信時刻とzKBのペイロードを含むJSON形式のメッセージを1/f秒ごとに1個,180秒間にわたって生成し,KafkaのトピックTopic1に書き込む.この際,メッセージの文字列長は72~85バイト+ペイロード長となる.また,Kafkaのメッセージ圧縮機能は無効とした.
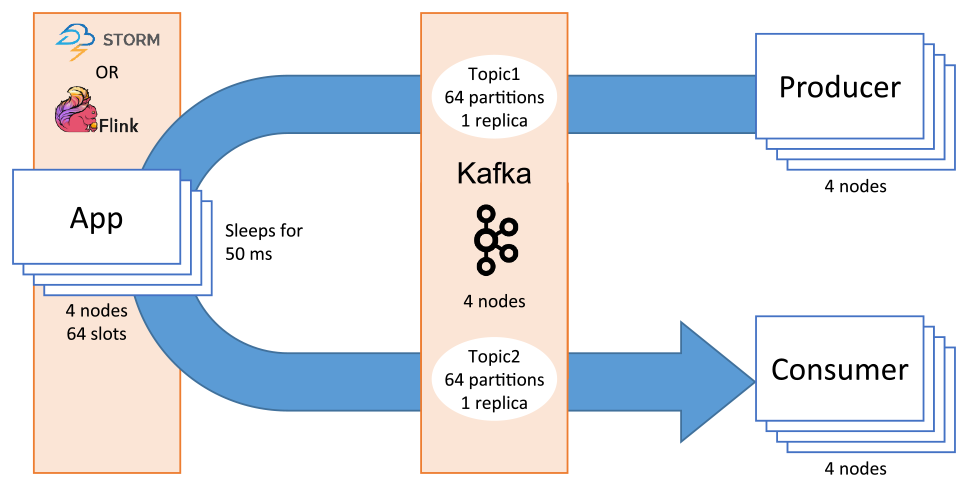
Fig. 11 Configuration of the distributed stream processing experiment.
メッセージを折り返すFlinkアプリとStormアプリはそれぞれ,各基盤上に実装されたJavaプログラムで,KafkaのトピックTopic1からメッセージを読み出し,一定時間待機した後,同じメッセージをKafkaのトピックTopic2に書き込む.待機時間は,アプリ内で何らかの処理がされることを想定している.アプリ内ではJSONを解釈せず,文字列としてデシリアライズ/シリアライズする.メッセージをKafkaから取り出すConsumerは単体のPythonプログラムで,KafkaのトピックTopic2からメッセージを読み出し,受信時刻とメッセージに含まれる送信時刻をローカルファイルに書き込む.
評価環境として,表3に示すクラスタをAWS上に構築した.Kafkaの各トピックのパーティション数は64,レプリケーション数は1,FlinkアプリとStormアプリの並列度はともに64,その他の設定はデフォルトとした.Producerは,Kafka Brokerと同じインスタンス上で一インスタンスにつき一つ,全体で四つのプロセスを走らせた.Consumerも同様である.ペイロードはz∈{1, 16, 64, 256, 1024} KB,送信頻度はf∈{1, 30, 60, 240, 320}個/秒(以後FPSと書く)とした.4台のProducerを合わせると,Kafka Brokerに流し込まれるペイロードの流量は全体で4zfKB/秒となる.アプリ内での待機時間は50ミリ秒とした.表4に実験で用いたパラメータをまとめた.
Table 3 Server specifications for the distributed stream processing experiment.
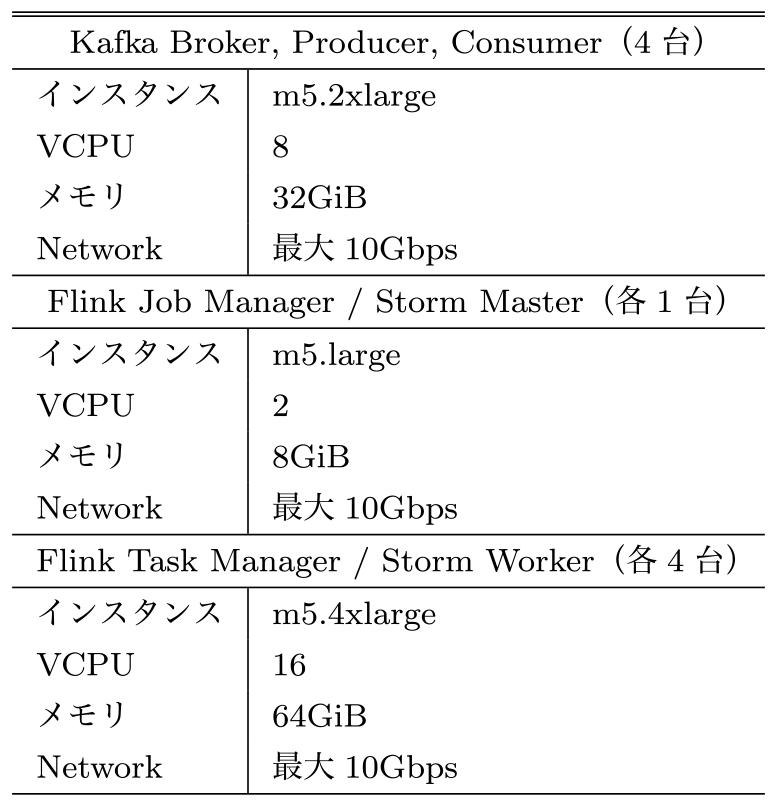
Table 4 Parameter settings for the distributed stream processing experiment.

評価値として,往復遅延とスループットを算出した.往復遅延は,各メッセージの送信時刻と受信時刻の差から,折り返し待機時間を引いたものである.ただし,ProducerとConsumerでJSONをシリアライズ/デシリアライズする時間は含まれている.スループットは,4台のConsumerが受信したペイロード量を4秒ごとに集計し,1秒あたりのバイト数に換算したものである.実験では,Kafkaはv. 2.2.0,Flinkはv. 1.7.2,Stormはv. 2.0.0を用いた.
3.4.2 評価結果
往復遅延の累積分布を図12に示す.左のグラフがFlinkの結果,右はStormの結果であり,縦軸は完了した処理要求の割合,横軸は遅延をミリ秒で表している.今回の評価ではペイロード量によって遅延が大きく変化しなかったため,ここではすべてのペイロード量を合わせた分布を示す.送信頻度が1 FPS~240 FPS(全体で4 FPS~960 FPS)の範囲では,90%のメッセージが240ミリ秒以下,99%のメッセージが500ミリ秒以下の遅延で往復していることが確かめられた.一方,送信頻度が320 FPS(全体で1280 FPS)に達すると遅延が徐々に累積し,最大で8228ミリ秒の遅延が観測された(Kafka+Flinkでz=256 KBのとき).メッセージの処理に50ミリ秒かかるアプリが64並列で動作しているので,理想的には全体で$\frac{1}{0.05} \times 64 = 1280\,{\rm FPS}$まで遅延なく処理できるはずだが,実際には種々のオーバーヘッドが加わるため,これは妥当な結果といえる.
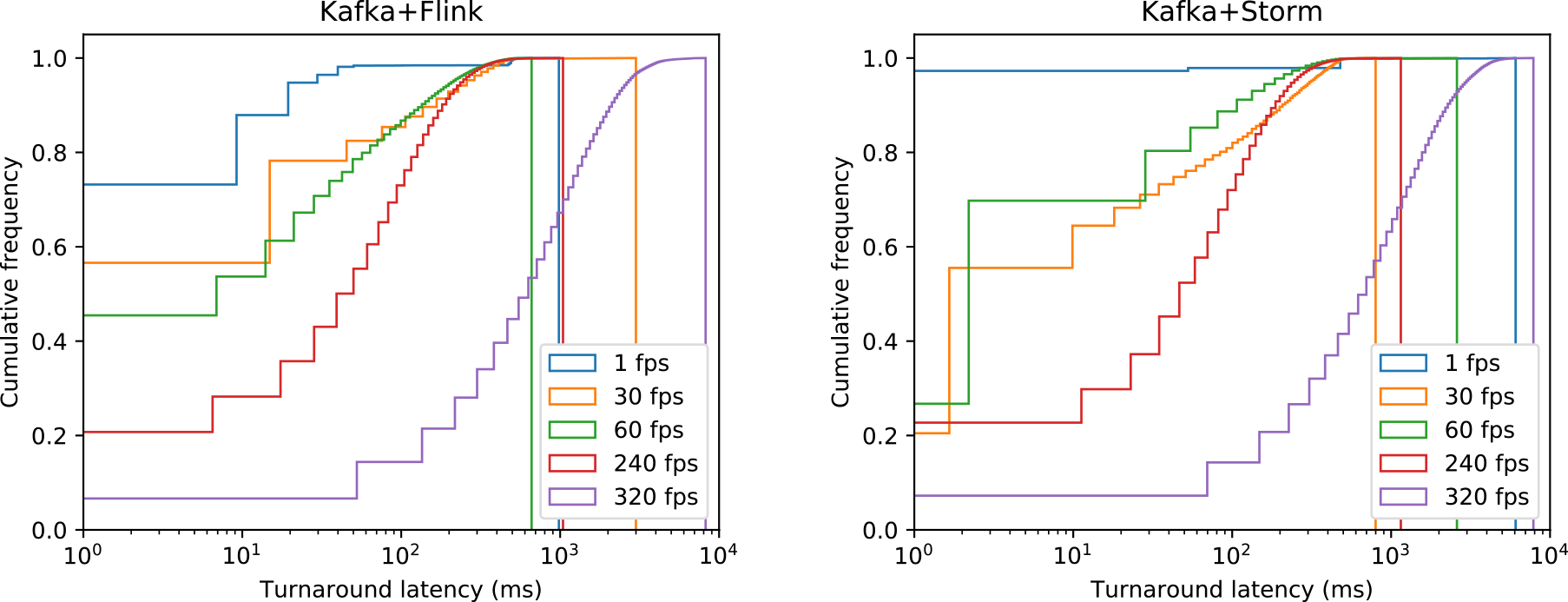
Fig. 12 Cumulative distribution of round trip latencies of all payload settings using Flink (left) and Storm (right). The vertical lines at the right end show the maximum latencies of each frame rate.
図13には,Flink(左)とStorm(右)の1秒ごとの最大往復遅延観測値をミリ秒で示す.横軸は経過時間となっている.ここでは,ペイロード量64 KBの場合の結果を示すが,他のペイロード量も同様の傾向を示していた.図12の結果で述べたように,320 FPSの結果では最大往復遅延値が大きくなっていくことが分かる.一方,1–240 FPSでは最大往復遅延値が一定程度で収まっているが,最大遅延値が瞬間的に大きく上下する現象が観測された.何らかの要因で数秒間メッセージが滞留し,その後一気に吐き出されたものと考えられる.このような秒単位のジッターがまれに発生することから,ストリーム処理基盤にミリ秒単位のオンライン性を期待するべきではないといえる.
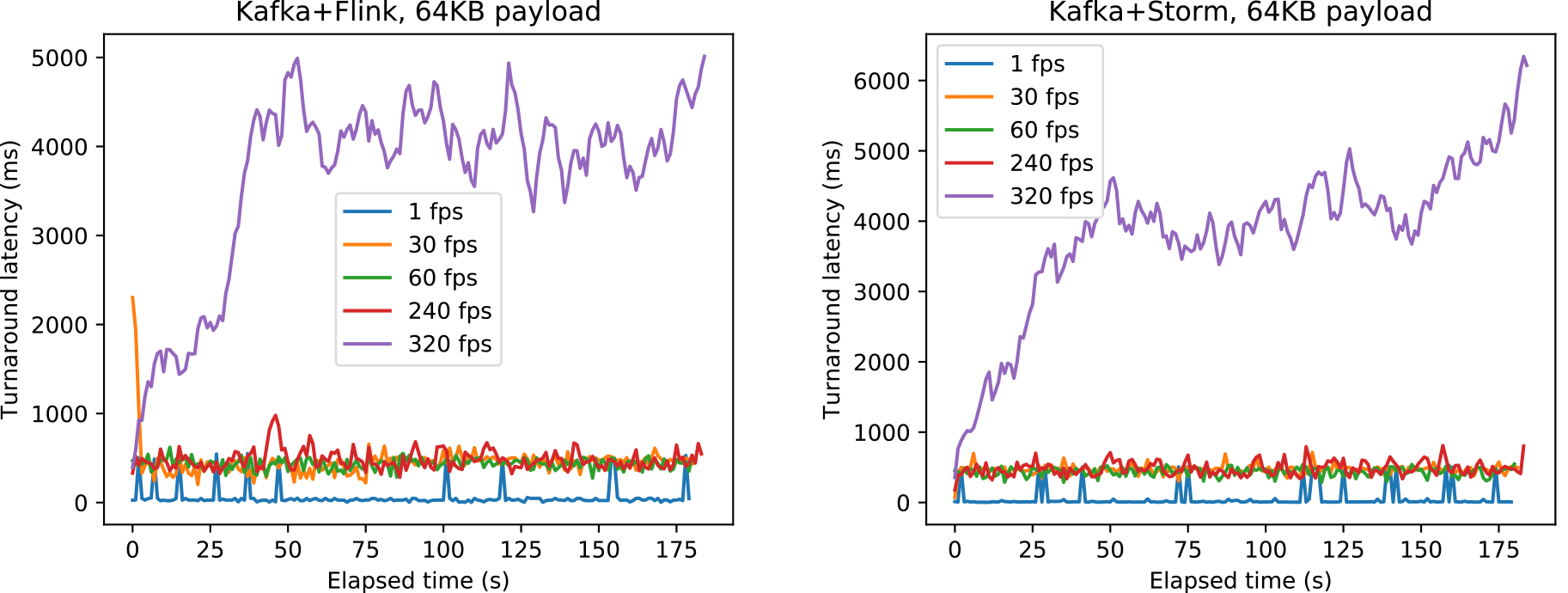
Fig. 13 Maximum round trip latencies per second when the payload amount is 64 KB using Flink (left) and Storm (right).
最後に,FlinkとStormのスループットの測定結果を図14に示す.始端と終端が落ち込んでいるのは,経過時間ではなく絶対時刻で4秒ごとに区切って集計したためである.ここではz=64 KBの結果のみを示したが,他のペイロード量でも同様の結果が得られた.図14から,送信頻度が高くなるにつれてジッターが大きくなる傾向が認められるものの,全体として4zfKB/秒を安定的に維持できていることが確かめられた.以上から,多少のオーバヘッドがあるものの既存分散ストリーム処理基盤を用いることで低遅延,高スループットで処理が可能であることが示唆された.
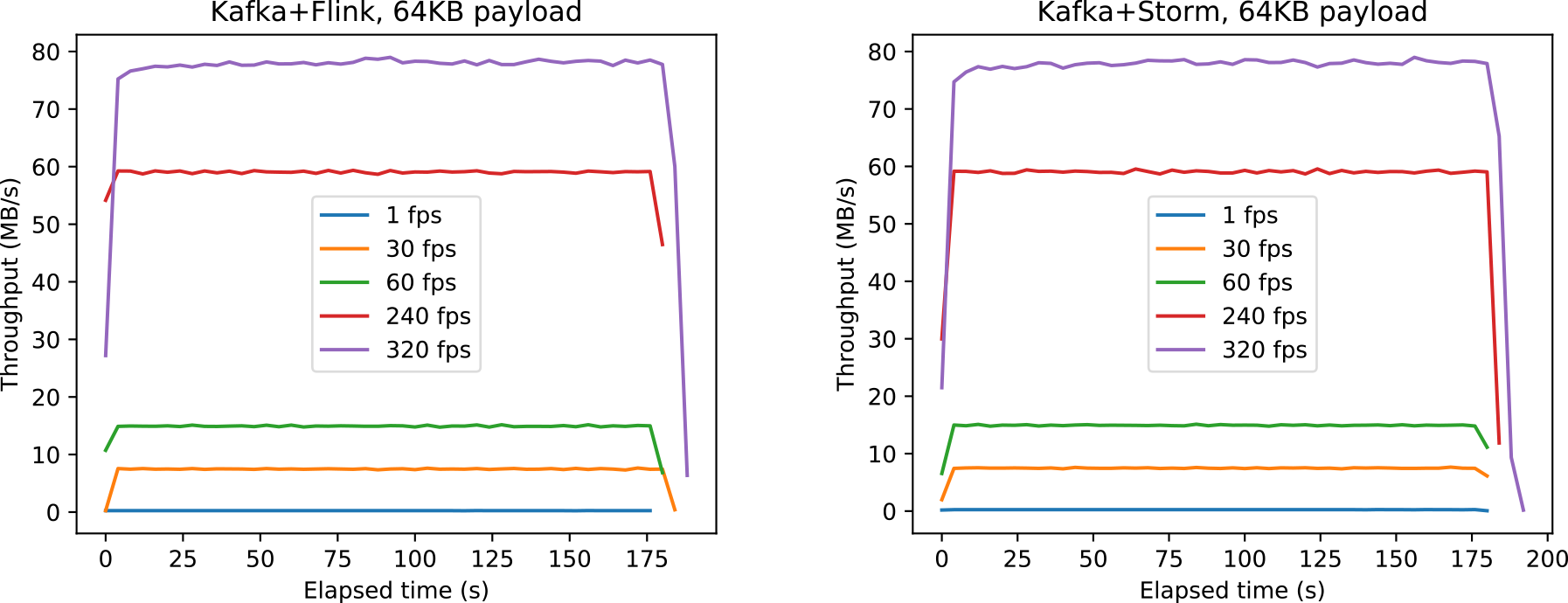
Fig. 14 Throughputs when the payload amount is 64 KB using Flink (left) and Storm (right).
4. 関連研究
多数のMQTTベースメッセージング基盤が実装されている.文献[35]やウェブサイト[36], [37]で複数MQTT実装の比較が行われている.VerneMQやApache ActiveMQなどクラスタ構成可能なBrokerを提供するソフトウェアもあり,今後比較していく.
文献[38]では,KafkaとRabbitMQの機能や性能を比較している.性能評価では,RabbitMQと1台構成のKafkaを比較し,メッセージサイズが2 KBまでの条件で同程度の性能を示している.本研究では,画像データ等も考慮した64 KBまでの比較と,クラスタ構成のKafkaの性能について調査している.
Apache Spark,Apache Storm,Apache Heron,Apache Flink, Apache Samzaなど,複数のストリームデータ処理基盤も開発されている.これらはメッセージング基盤と連携し,複数の計算ノードを活用して高度な処理を高スループットで行うことを目指して設計されている.ストリームデータ処理基盤を利用したシステムの構築では,性能面からKafkaと連携する試みが多い[39],[40].また,オープンソースソフトウェアではなく商用クラウドのストリームデータ処理基盤を利用する選択肢もある.文献[41]では,KafkaとAmazon Kinesisを比較して,コストと性能のトレードオフを議論している.
5. おわりに
オンラインビデオ処理では,センサとクラウド間のネットワーク帯域と安全性の確保,大量データの収集,クラウドでのオンラインビデオ解析処理の性能が課題となる.本研究では,SINET広域データ収集基盤を用いたオンラインビデオ処理機構のプロトタイプシステムを構築し,安全かつ高性能なネットワーク環境下でメッセージング基盤を利用した大量データの収集と,クラウドのGPUノードを活用したオンライン処理が実現可能であることを示し,実証実験環境の構築および実施の際に用いたプログラムを「SINET広域データ収集基盤デモパッケージ」としてGitHubで公開した.
また,予備評価によりオンプレミスおよびクラウドのオブジェクトストレージの基本性能と,KafkaとMosquittoの性能,FlinkとStormの性能を調査した.実験から,大量のセンサデータを扱うにはオブジェクトストレージでは不十分でメッセージング基盤を活用することが望ましいこと,MQTTベースのMosquittoはクライアント用のライブラリが充実しているという利点もあるが,大量データのデータ収集にはKafkaが優位であること,IoTアプリケーションの要件に合わせてソフトウェア構成を設計する必要があることを示した.また,分散ストリーム処理基盤では多少のオーバヘッドがあるものの,低遅延,高スループットでの処理が期待できることが分かった.広帯域,低遅延の5G環境とメッセージング基盤,分散ストリーム処理基盤を適切に組み合わせることで,秒単位の応答時間を許容するIoTアプリケーションの構築が可能であることが示された.
我々は,現在広域に分散するデータを収集,解析する研究を支援するソフトウェアパッケージSINETStreamを開発し,オープンソースとして公開している[42],[43].本稿で示したように,メッセージング基盤ミドルウェアごとに性能特性が異なるため,IoTアプリケーション開発初期の段階で適切なミドルウェアを選択するのは難しい.しかし,メッセージング基盤ミドルウェアごとにAPIが異なるため,ミドルウェアの変更には大幅なプログラムの書き換えが必要となる.よって,SINETStreamではそれらを抽象化するAPIを提供している.また,認証・認可,暗号化といった安全性を高めるための機能も提供している.SINETStreamにより,安全かつ高効率なIoTアプリケーションの開発・運用を容易にする技術の開発を行っていく.
謝辞 本研究を進めるにあたり,貴重なご意見をいただいたジョージア工科大学のCalton Pu教授,デモパッケージの開発および評価にご協力いただいた数理技研の小泉敦延様,鯉江英隆様に深く感謝いたします.本研究成果の一部は,JSPS科研費JP19H04089および,2019年度国立情報学研究所公募型共同研究(19S0501)の助成を受けて実施されたものである.
参考文献
- [1] MQTT (Message Queue Telemetry Transport), http://mqtt.org/.
- [2] SINET広域データ収集基盤,https://www.sinet.ad.jp/wadci.
- [3] 竹房あつ子,孫 静涛,長久 勝,吉田 浩,政谷好伸,合田憲人:SINET広域データ収集基盤を用いたリアルタイムビデオ処理機構の検討,マルチメディア,分散,協調とモバイル(DICOMO2019)シンポジウム論文集,pp.1581–1588 (2019).
- [4] 孫 静涛,藤原一毅,竹房あつ子,長久 勝,吉田 浩,合田憲人:SINET広域データ収集基盤のための基盤ソフトウェアの検討,情報処理学会研究報告,2019-OS-147, pp.1–9 (2019).
- [5] Ichinose, A., Takefusa, A., Nakada, H. and Oguchi, M.: A Study of a Video Analysis Framework Using Kafka and Spark Streaming, Proc. Second Workshop on Real-time & Stream Analytics in IEEE Big Data, pp.2396–2401 (2017).
- [6] Kreps, J., Narkhede, N. and Rao, J.: Kafka: a Distributed Messaging System for Log Processing, NetDB workshop 2011, pp.1–5 (2011).
- [7] Shree, R., Choudhury, T., Gupta, S. C. and Kumar, P.: KAFKA: The modern platform for data management and analysis in big data domain, 2017 2nd International Conference on Telecommunication and Networks (TEL-NET), pp.1–5 (online), DOI: 10.1109/TEL-NET.2017.8343593 (2017).
- [8] Apache Kafka, https://kafka.apache.org/.
- [9] Redmon, J. and Farhadi, A.: YOLOv3: An Incremental Improvement, CoRR, Vol.abs/1804.02767 (online), available from 〈http://arxiv.org/abs/1804.02767〉 (2018).
- [10] YOLO, https://pjreddie.com/darknet/yolo/.
- [11] A PyTorch implementation of the YOLO v3 object detection algorithm, https://github.com/ayooshkathuria/pytorch-yolo-v3.
- [12] Wei, S.-E., Ramakrishna, V., Kanade, T. and Sheikh, Y.: Convolutional Pose Machines, CVPR (2016).
- [13] Simon, T., Joo, H., Matthews, I. and Sheikh, Y.: Hand Keypoint Detection in Single Images using Multiview Bootstrapping, CVPR (2017).
- [14] Cao, Z., Simon, T., Wei, S.-E. and Sheikh, Y.: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields, CVPR (2017).
- [15] Cao, Z., Hidalgo, G., Simon, T., Wei, S.-E. and Sheikh, Y.: OpenPose: realtime multi-person 2D pose estimation using Part Affinity Fields, arXiv preprint arXiv: 1812.08008 (2018).
- [16] OpenPose, https://github.com/CMU-Perceptual-Computing-Lab/openpose.
- [17] Takefusa, A., Yokoyama, S., Masatani, Y., Tanjo, T., Saga, K., Nagaku, M. and Aida, K.: Virtual Cloud Service System for Building Effective Inter-Cloud Applications, Proc. CloudCom 2017, pp.296–303 (2017).
- [18] 学認クラウド,https://cloud.gakunin.jp/.
- [19] SINET広域データ収集基盤デモパッケージ,https://github.com/nii-gakunin-cloud/wadci-demo.
- [20] Light, R.: Mosquitto: server and client implementation of the MQTT protocol, The Journal of Open Source Software, Vol.2, pp.1–2 (online), DOI: 10.21105/joss.00265 (2017).
- [21] Eclipse Mosquitto, https://mosquitto.org/.
- [22] Apache Flink, https://flink.apache.org/.
- [23] Apache Storm, https://storm.apache.org/.
- [24] Apache Spark, https://spark.apache.org/.
- [25] Karakaya, Z., Yazici, A. and Alayyoub, M.: A Comparison of Stream Processing Frameworks, 2017 International Conference on Computer and Applications (ICCA), pp.1–12 (2017).
- [26] Nasiri, H., Nasehi, S. and Goudarzi, M.: Evaluation of distributed stream processing frameworks for IoT applications in Smart Cities, J. Big Data, Vol.6, No. 52, pp.1–24 (online), DOI: 10.1186/s40537-019-0215-2 (2019).
- [27] AI/SUM SHOWCASE, https://aisum.jp/showcase/.
- [28] 吉田 浩,合田憲人,上田郁夫,原 隆宣,小杉城治,森田英輔,中村光志:クラウドコールドストレージに対する大規模実験データ格納のケーススタディ,情報処理学会研究報告2018-HPC-165, pp.1–10 (2018).
- [29] goofys, https://github.com/kahing/goofys.
- [30] Jupyter Notebook, http://jupyter.org/.
- [31] Yokoyama, S., Masatani, Y., Ohta, T., Ogasawara, O., Yoshioka, N., Liu, K. and Aida, K.: Reproducible Scientific Computing Environment with Overlay Cloud Architecture, Proc. 9th IEEE Cloud, pp.774–781 (2016).
- [32] 国立研究開発法人情報通信研究機構:製造現場における無線ユースケースと通信要件(要約版),技術報告,FLEXIBLE FACTORY PARTNER ALLIANCE (FFPA) (2017).
- [33] COSBench - Cloud Object Storage Benchmark, https://github.com/intel-cloud/cosbench.
- [34] MQTT-Bench: MQTT Benchmark Tool.
- [35] Patro, S., Potey, M. and Golhani, A.: Comparative study of middleware solutions for control and monitoring systems, 2017 Second International Conference on Electrical, Computer and Communication Technologies (ICECCT), pp.1–10 (online), DOI: 10.1109/ICECCT.2017.8117808 (2017).
- [36] Wikipedia: Comparison of MQTT implementations, https://en.wikipedia.org/wiki/Comparison_of_MQTT_implementations.
- [37] MQTT community website, server support, https://github.com/mqtt/mqtt.github.io/wiki/server-support.
- [38] Dobbelaere, P. and Esmaili, K. S.: Kafka Versus RabbitMQ: A Comparative Study of Two Industry Reference Publish/Subscribe Implementations: Industry Paper, Proceedings of the 11th ACM International Conference on Distributed and Event-based Systems, DEBS '17, pp.227–238 (online), DOI: 10.1145/3093742.3093908 (2017).
- [39] Javed, M. H., Lu, X. and Panda, D. K. D.: Characterization of Big Data Stream Processing Pipeline: A Case Study Using Flink and Kafka, Proceedings of the Fourth IEEE/ACM International Conference on Big Data Computing, Applications and Technologies, BDCAT '17, pp.1–10 (online), DOI: 10.1145/3148055.3148068 (2017).
- [40] Kato, K., Takefusa, A., Nakada, H. and Oguchi, M.: A Study of a Scalable Distributed Stream Processing Infrastructure Using Ray and Apache Kafka, 2018 IEEE International Conference on Big Data (Big Data), pp.5351–5353 (online), DOI: 10.1109/BigData.2018.8622415 (2018).
- [41] Nguyen, D., Luckow, A., Duffy, E. B., Kennedy, K. and Apon, A.: Evaluation of Highly Available Cloud Streaming Systems for Performance and Price, Proceedings of the 18th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing, CCGrid '18, pp.360–363 (online), DOI: 10.1109/CCGRID.2018.00056 (2018).
- [42] SINETStream, https://www.sinetstream.net/.
- [43] 竹房あつ子,孫 静涛,藤原一毅,吉田 浩,合田憲人:IoTストリームデータ処理のためのソフトウェアライブラリSINETStreamの開発,情報処理学会研究報告2020-IOT-48, pp.1–8 (2020).

竹房 あつ子(正会員)
2000年博士(理学)(お茶の水女子大学)取得.日本学術振興会特別研究員(DC2,PD),お茶の水女子大学大学院助手,産業技術総合研究所研究員,主任研究員を経て2016年より国立情報学研究所アーキテクチャ科学研究系准教授,総合研究大学院大学複合科学研究科情報学専攻准教授兼務.並列分散処理,グリッド,クラウド,エッジ,IoTに関する研究に従事.ACM,IEEE,電子情報通信学会各会員.

孫 静涛(正会員)
1987年生.2013年東京工科大学大学院バイオ情報メディア研究科コンピュータサイエンス専攻博士課程前期修了.2016年総合研究大学院大学複合科学研究系情報学専攻博士課程後期修了.博士(情報学).同年国立情報学研究所アーキテクチャ科学研究系特任研究員.分散システム,クラウドコンピューティング,IoTの研究に従事.ACM,IEEE,CCF各会員.

藤原 一毅(正会員)
国立情報学研究所オープンサイエンス基盤研究センター特任准教授.博士(情報学).2012年,総合研究大学院大学複合科学研究科情報学専攻を修了.同年より,国立情報学研究所アーキテクチャ科学研究系特任研究員として計算機ネットワークを研究.2016年より,情報通信研究機構ユニバーサルコミュニケーション研究所データ駆動知能システム研究センター主任研究員として自然言語処理向け高性能計算システムを設計.2018年より現職にてNII Research Data Cloudを構成するデータ解析システムの開発に従事.

長久 勝(正会員)
ライフマティックス株式会社ライフサイエンス事業部リードエンジニア・主任研究員.1994年3月龍谷大学理工学部数理情報学科卒業.1994年3月株式会社エス・エヌ・ケイ入社.以降,コンピュータゲーム開発や動画配信などに従事.奈良女子大学,早稲田大学にて非常勤講師.国立情報学研究所にてトップエスイーやクラウド関連の業務に従事.2019年4月よりライフマティックス株式会社に在籍.日本デジタルゲーム学会会員.

吉田 浩(正会員)
1978年東京大学工学部電子工学科卒業.1980年同大学大学院工学系研究科修士課程修了.富士通株式会社において,ソフトウェア,ストレージシステム,パブリッククラウドサービスの企画・開発に従事.2015年より国立情報学研究所クラウド基盤研究開発センターにおいて,クラウド関連の研究・開発および大学・研究機関のクラウド導入支援に従事.IEEE会員.

政谷 好伸
名古屋大学理学部物理学専攻科修了,NTT電気通信技術研究所,インターネットサービスプロバイダ,システムインテグレータなど勤務.2014年より国立情報学研究所先端ICTセンター特任研究員.クラウド関連の研究・開発・運用業務に従事.ACM会員.

合田 憲人(正会員)
1997年博士(工学)(早稲田大学)取得.1992年早稲田大学情報科学研究教育センター助手,1997年東京工業大学大学院情報理工学研究科数理・計算科学専攻助手,1999年同大学大学院総合理工学研究科知能システム科学専攻講師,2003年同研究科物理情報システム専攻助教授,2007年国立情報学研究所特任教授,2015年同教授,現在に至る.科学技術振興機構さきがけ研究員(2001年~2005年),ハワイ大学Information and Computer Sciences Department客員研究員(2007年),東京工業大学大学院総合理工学研究科物理情報システム専攻連携教授(2007年~2016年),総合研究大学院大学複合科学研究科情報学専攻教授(2008年~現在)等を兼任.電子情報通信学会,IEEE,ACM各会員.
再受付日 2020年6月3日
採録日 2020年07月15日