日本最大級の女性向けコミュニティサイトにおける違反コンテンツ検閲システムの構築―安心して使い続けてもらうためのコミュニティを目指して―
1.はじめに
筆者が所属するConnehito(株)が運営するmamariQ[1]は日本で最大級の女性向けCommunity Question Answering (以下,CQAと略す)サイトである.CQAサイトとはユーザの投稿した質問に対して,ほかのユーザが回答を寄せるサイトのことを言う.日本においては,Yahoo!知恵袋に代表される.活発なCQAサイトにおいては,必ず「荒らし」と呼ばれる,本来のCQAの利用用途にそぐわない投稿を行うユーザが現れる.本稿では,スタートアップがサービスの成長を止めずに限られたリソースを用いて効果的に不適切な投稿に対応した方法を実例を元に述べる.
2.背景・課題
2.1 サービス規模
妊娠・出産・子育ての疑問を解決する女性のためのQ&AサイトmamariQには,厚生労働省発表の人口動態統計[2]から算出すると2015年に出産予定日を迎えた人の10人に1人以上が登録しており,国内最大級の家族向けサービスに成長している.このような状況の中,mamariQのユーザ数増加とともにコミュニティを荒らすようなガイドラインに違反した不適切なコンテンツの投稿が多く見られるようになった.
2.2 監視におけるリソース不足
サービス運営当初はすべての投稿を人手で監視していたが,開発当時ディレクタ1人,エンジニア2人でプロダクト開発を継続して行わなければならないという状況であったため,すべての投稿を監視し続けるのは現実的ではなかった.
そこでサービス初期の段階では,単語の部分一致を用いて特定の単語を含むもののみ検閲を行った.また,サービスの成長とともに検閲の量も多くなったので,担当者を1人つけることにした.しかし,サービスが成長し現在の規模,すなわち月間約80万件のコンテンツ投稿が行われるようになると,不適切なコンテンツ検閲のための監視対象投稿数は1日あたり数千件に上り,投稿の検閲を目視で行う方法では監視が間に合わなくなった.
2.3 開発におけるリソース不足
以上のような背景から目視での投稿監視は難しくなったため,何かしらのシステムでこの問題を解決することにした.しかしながら,成長し続けなければならないスタートアップにとって,費用対効果の見えないこのようなシステムの開発業務に対して十分な時間を割くことは難しい.なぜなら業務時間中はアプリケーション本体の開発に時間を割く必要があったからである.そこで業務時間外の時間を利用し,限られた時間内で精度を向上させ,実運用に持っていく必要があった.
2.4 不適切な投稿に対応することの重要性
過去の回答が閲覧可能なCQAにとって,ガイドラインに違反したコンテンツの投稿はクリティカルな問題となる.なぜなら,ユーザは少しでもコミュニティが荒れた雰囲気を感じると投稿を控えるようになるからである.以下は実際にユーザから送られてきた違反報告の文章の一部である.
「正直,せっかく投稿したのにそれを攻撃されるなら,もう投稿したくないしアプリに足も運びたくなくなります.たまたま否定的な意見の人が集まると,いじめのような状態になっていて,怖いです」
上記のように感じるユーザを減らすため不適切な投稿に対応することはコミュニティ運営上非常に重要な意味を持つことが分かる.
3.機械学習によるアプローチ
検閲が必要なコンテンツの投稿かどうかを,機械学習を用いて判別することにした.自然言語処理における文章分類ではいくつかの手法が存在するが,今回は
- 1) 形態素解析システム(MeCab[3])で質問文から単語を切り出し,
- 2) 1の単語を元に特徴語辞書を準備し,
- 3) 各文章の特徴語をカウントして特徴ベクトルを作成し,
- 4) 学習器を用いて分類する
というシンプルな方法で分類器を開発し,検閲を自動化することにした.また,素性としては名詞,動詞,形容詞,記号を用いた.
4.実運用へ向けた試行と,実践で生まれた運用フロー
4.1 精度向上への取り組み
4.1.1 指標検証のためのデータセット
過去に運用した中で,目視により「不適切な投稿である」と判断した投稿1,000件と通常の投稿1,000件を用意し,合計2,000件の投稿に対して2値分類を行うことにした.
4.1.2 目標とすべき指標数値の定義
不適切な投稿かどうかを「正しく判別している」ことを定量的に計るため,precision, recall, F-measure, accuracy[4]を比較する値として利用する.目標とすべき指標数値として,不適切な投稿を見逃さないことが最重要であるので,不適切な投稿のrecallを1に近づけることを第1目標とする.またその条件下で通常の投稿を不必要に不適切な投稿として分類しないようprecisionを実用上十分なまで上げることが第2目標である.これら2つの目標を達成することで,アプリケーションは実運用が可能になり,安心して使い続けてもらえるコミュニティを作ることに繋がる.
4.1.3 学習器の選定
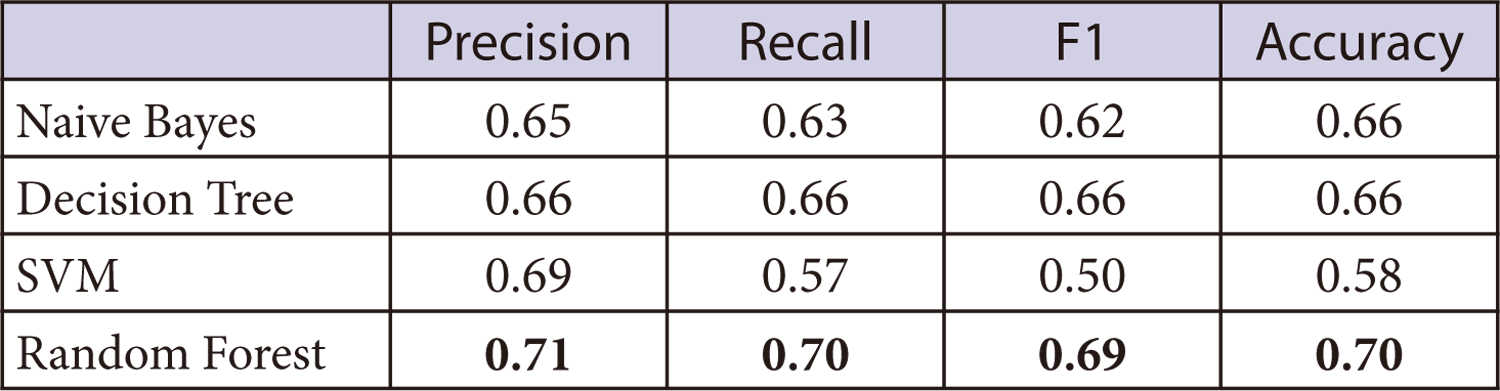
まず,学習器の選定を行った.比較対象となる学習器はNaive Bayes, Decision Tree, SVM[5], Random Forest[6]である.なお,以後の実験での評価は,すべて5-fold cross validationで行った.
それぞれの学習器で4.1.1節のデータを分類した結果を表1に示す.最も結果が良かったのはRandom Forestであった.しかし,それでもprecision, recallともに0.7程度であった.さまざまな学習器を試すことやパラメータのチューニングなど,時間が十分にあれば学習器について改善を行うことも可能であるが,割くことのできるリソースは限られていた.かつ実導入のニーズがサービスの成長とともに高まっていたので,精度向上の効果が低かった学習器を変えるというアプローチから,「辞書を拡充し,愚直に辞書データを精査する」というアプローチに変更した.また,辞書の拡充にあたってシステム辞書自体も精査することにした.
4.1.4 システム辞書の選定
4.1.3節ではMeCab標準のシステム辞書であるipadicを用いたが,ほかのシステム辞書を利用することで精度が上がることが期待できると考えた.そこで,それらのシステム辞書の選定を行った.候補としてはipadic以外に jumandic, unidicとさらにipadicと併用可能なmecab-ipadic-NEologd[7]が挙げられる.
mecab-ipadic-NEologdとは,多数のWeb上の言語資源から得た新語を追加することにより拡張したMeCab 用のシステム辞書である.mecab-ipadic-NEologdを利用してMeCabを実行した結果とipadicで実行した結果をそれぞれ図1,図2に示す.


この2つの図を見ると「メールレディ」という単語がipadicでは「メール」という単語と「レディ」という単語に分割され,mecab-ipadic-NEologdでは「メールレディ」という1単語に分割されていることが分かる.mamariQにおいては「メールレディ」に関する投稿は違反コンテンツである割合が高いため,mecab-ipadic-NEologdの方が正しい良い分割をしていると考えられる.また,末尾の顔文字についてはmecab-ipadic-NEologdでは意味を示すフリガナがふられていることが分かる.以上より,mecab-ipadic-NEologdの方が文章の内容をより理解するための情報を得ることができる.
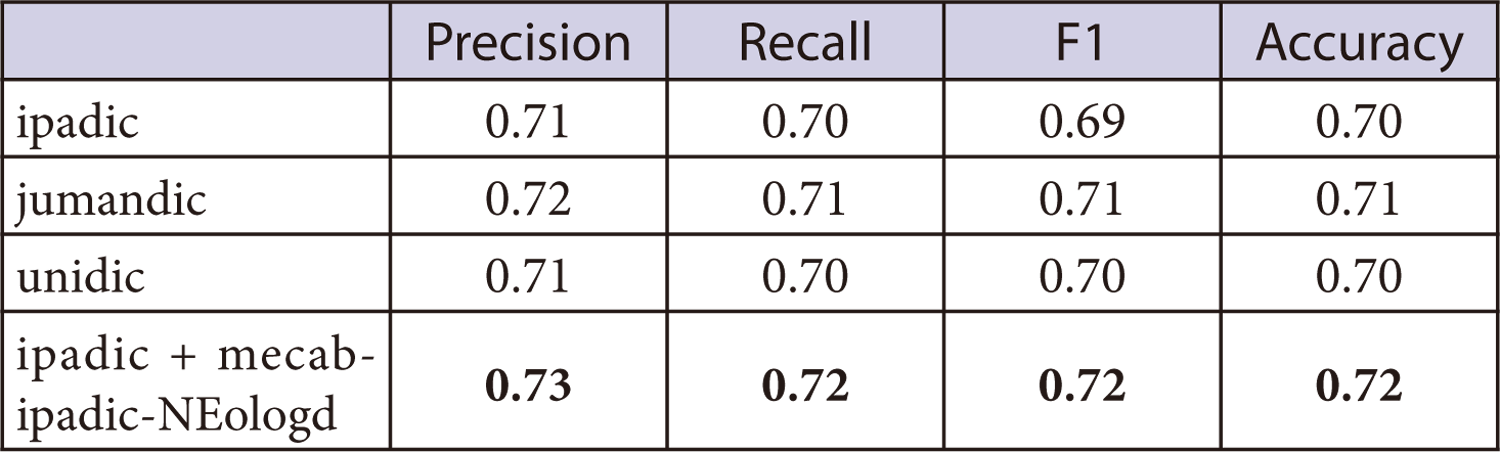
mecab-ipadic-NEologdを含めた各辞書で最も良い辞書を選定するために,学習器の比較で最も結果の良かったRandom Forestを用いて辞書の比較を行った.ipadic, jumandic, unidic, ipadicにmecab-ipadic-NEologd加えてそれぞれで実際に判別を行った結果を表2に示す.表2よりipadicとmecab-ipadic-NEologdの併用が最も良い結果となったことが分かる.
スマートフォンベースのサービスであるmamariQには絵文字や顔文字,Web上でよく使用されるスラングやより一般的な会話の中で使われる単語等が利用されるため,結果に改善が見られたのだと考えられる.よって,mecab-ipadic-NEologdをシステム辞書として採用することにした.
4.1.5 辞書の拡充
システム辞書にmecab-ipadic-NEologd を利用することにより,単語の分割精度を高めることができたが,本サービス特有の単語は網羅されていなかった.そこで網羅できていない,本サービス特有の単語を追加・調整することにより,精度の向上に取り組んだ.その辞書拡充のステップを図3に示す.

辞書の拡充自体は非常に愚直な作業である.ユーザから違反報告があがったコンテンツに対して,目視で何がその違反の原因だったのかを判断し,分類に適した単語があれば辞書に追加していく.
具体例として,「ビジネスパートナー」という単語を辞書登録するかの判断について説明する.mamariQにおける 「ビジネスパートナー」という単語を用いた投稿はユーザをネットワークビジネスへ勧誘する投稿であることが多い.たとえば以下のような投稿である.
「はじめまして,私は今妊娠中ですが家からの仕事で旦那より稼いでます.一緒に仕事をするビジネスパートナーを募集中です.もし興味があれば連絡先を交換しませんか?」 この文章を形態素解析すると,「ビジネス」と「パートナー」という2つの名詞と認識される.このような単語の場合,「ビジネスパートナー」を1語として認識させるために,単語として辞書登録を行う.
ユーザからの違反報告に向き合い,合計約2,000単語について検討,精査を行い,辞書の拡張を続けた.4.1.1節のデータセットに対して拡張した辞書を利用し,学習器(Random Forest)を用いて判別を行ったところ,各指標は表3に示す値となった.結果としてprecision, recallともに0.8以上となった.サービス開始時から現在までにあがってきた違反報告を確認し,網羅した段階で実用化への取り組みをスタートすることにした.約2万件近くの違反報告を精査することは簡単ではなかったが,辞書の拡張の過程で精度が上がることが明確に分かったので,チームメンバに協力を仰ぎながら地道に作業を進めた.

4.1.6 サンプリングした実データを用いた閾値チューニング
ここまでの実験において,不適切な投稿と通常の投稿は1対1の割合のデータセットを用いていた.しかし,実際には不適切なコンテンツの割合は通常の投稿に比べてごく少数である.直近で行われた投稿約100万件の実データから1,000件をランダムサンプリングし,内容を確認したところ不適切な投稿は12件であった.この1,000件に対して,学習済みの学習器により判別を行ったところ,表4に示す結果となった.違反コンテンツのrecallが1.00であることから,学習器による判別によって違反コンテンツの投稿がすべて検知できていることが分かる.一方で,一部の本来は通常のコンテンツとして判別されるべきデータが不適切な投稿として判別されているため,違反コンテンツにおける,precisionの値が低い.そこで,scikit-learn[8]のRandomForestClassifierを用いてprobabilityを出力させ,その判別の閾値を調整することにした.probabilityを確認すると,通常コンテンツだが違反コンテンツとして判別された投稿の多くはprobabilityが0.5~0.74であることが分かった.そこで,デフォルトの設定における閾値は0.5であるが,0.74という閾値に変えた結果,表5に示す結果となった.違反コンテンツすべてを検知しつつ,通常コンテンツを違反なコンテンツとして判別される件数を大幅に削減することができた.


4.2 機械学習と目視での投稿内容確認の併用による実運用へ
4.2.1 クリティカルな分類ミスの存在
実際にアプリケーションに検閲システムを導入してみると,分類ミスは少ないが,運用上きわめて不適切なコンテンツでもあるにもかかわらず,適切と分類してしまう場合を0にすることはできなかった.たとえば,一見普通の投稿に見えるが,実はブログのリンク先はユーザを不適切なコンテンツの閲覧へと誘導させる以下のような投稿である.
「みなさん子育てで参考にしている
本や人,ブログなどありますか??
おすすめなどあれば教えてほしいです(^-^)/
私はこの方のブログを参考にさせてもらってます!
優しい気持ちになれるので,めちゃめちゃお勧めです!
(^^) http://xxx.xxx.xxx(不適切なコンテンツ閲覧へと誘導させるリンク)」
4.2.2 ユーザのための運用フローを構築
CQAにとって,ガイドラインに違反したコンテンツの投稿はクリティカルな問題となる(2.4節を参照).そこで,機械学習と目視での投稿内容確認の併用によってこの問題に対して取り組んだ.実運用では4.1.6節と同様にscikit-learnのRandomForestClassifierを用いて,投稿コンテンツごとに違反コンテンツであるprobabilityを出力させ,それが一定の閾値を越える場合に人に判断を促すようなアラートを出すという工夫を行った.図4にシステム全体のフローを示す.
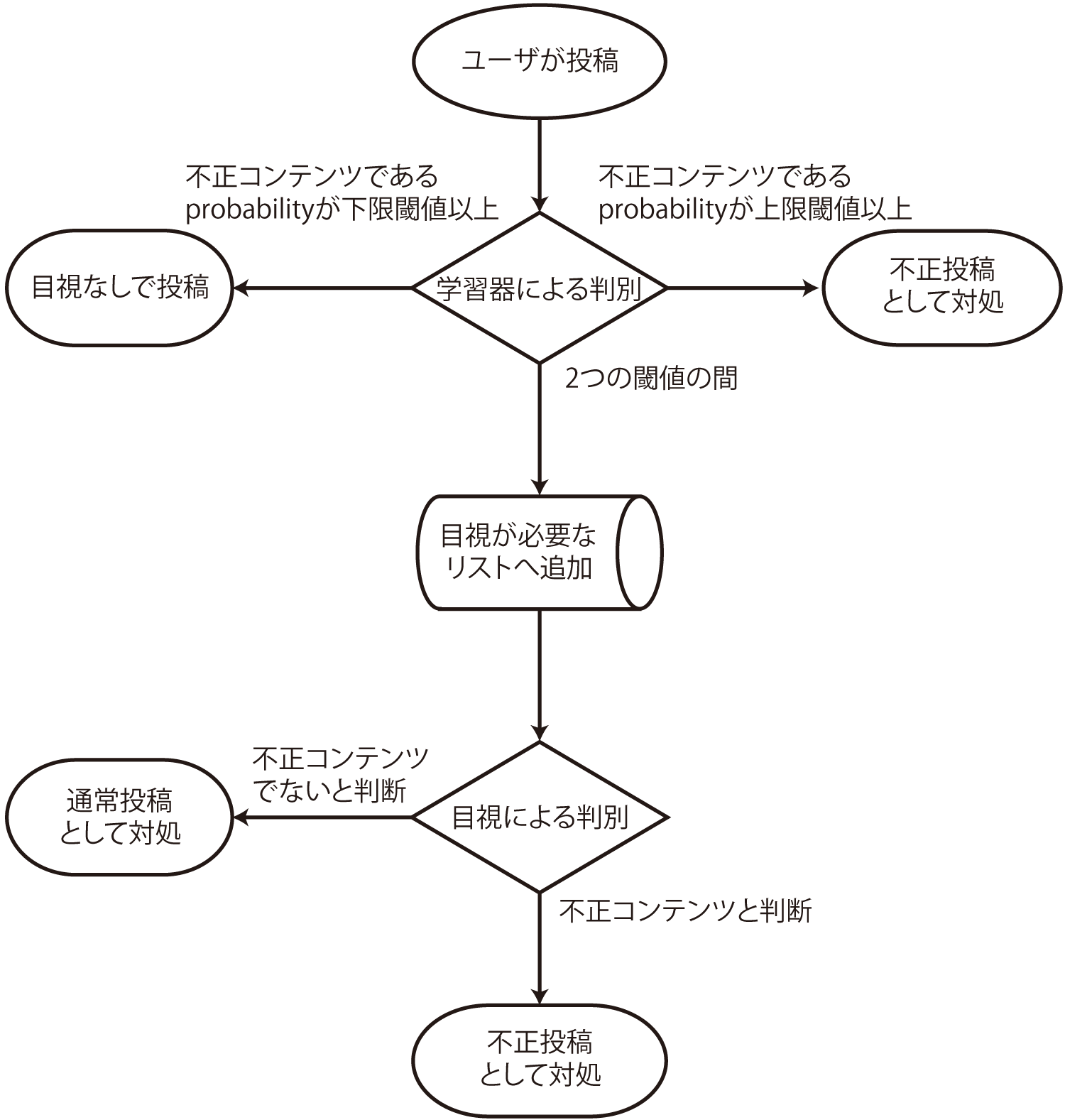
まず,ユーザからの投稿はあらかじめ学習したモデルに従い判別する.このとき,不正なコンテンツであるというprobabilityが上限閾値以上である場合は不正コンテンツとして対処し,逆に下限閾値以下であった場合には通常の投稿として扱う.scikit-learnにおけるRandomForestClassifierのTrue or Falseの閾値を0.74に設定した上で,人に判断を促すアラートを出す下限閾値は執筆時点では0.6,上限閾値を0.74として指定している.その理由は,false negativeな判定をしてしまった投稿を発見するためである.false negativeな判定とはすなわち,本来は不適切なコンテンツであるが,そうでないと判定したということである.繰り返しになるが,そのような投稿はコミュニティにとってクリティカルな影響を及ぼす投稿となる(2.4節を参照)ので,ここの誤判定を0に近づけるためにこのような2つの閾値を設定した.probabilityが2つの閾値の間に含まれた場合,その投稿に対しては,目視での投稿内容確認が必要なコンテンツとしてリストに登録する.そしてそのリストに登録されたコンテンツを人間が判断し,不正かどうかを判別する.機械学習を最大限利用するが,あえてすべては自動化しないことで,結果としてコミュニティにとって大事な検閲の精度を高め,運用可能なフローとなった.
このシステム導入後,人手による判別が必要と判断される投稿は1日あたり200件程度となった.この件数は全投稿の1%以下である.これにより,1日数回,リストに登録されたコンテンツをチェックする程度で検閲が完了している.
5.おわりに
現在も継続的かつ定期的に辞書のアップデートを行いながら今の閾値が適切かどうかの確認を行っている.多くの研究では数%の精度について最新の学習アルゴリズムを用いて競い合うことが多いが,現実に適用する際には,非常に愚直で時間はかかるものの,辞書の整備が確実で効果的であることが分かった.また,すべてを機械学習で解決するのではなく人手との併用によって,リソースの限られたスタートアップで現実に適用できるシステムの構築を行うことができた.今後は画像付きの投稿に対しても機械学習を用いたシステムによる画像判別を導入していきたいと考えている.
謝辞 本稿におけるプラクティスに尽力されたConnehito(株)のチームメンバに感謝の意を表します.
参考文献
- 1)mamariQ, 家族の毎日を笑顔にする女性限定Q&Aアプリ,http://qa.mamari.jp(2016年5月21日現在)
- 2)厚生労働省 平成27年人口動態統計月報年計(概数)の概況,http://www.mhlw.go.jp/toukei/saikin/hw/jinkou/geppo/nengai15/index.html (2016年5月21日現在)
- 3) Kudo, T., Yamamoto, K. and Matsumoto, Y. : Applying Conditional Random Fields to Japanese Morphological Analysis, Proc. Empirical Methods in Natural Language Processing (EMNLP-2004), pp.230-237 (2004).
- 4)Sammut, C. and Webb, G. I. (Eds.) : Encyclopedia of Machine Learning, Springer, pp.291-292 (2010).
- 5)Cortes, C. and Vapnik, V. : Support-vector Network. Machine Learning, Vol.20, pp.273-297 (1995).
- 6)Breiman, L. : Random Forests, Machine Learning, Vol.45, No.1, pp.5-32 (2001).
- 7)Sato, T. : Neologism Dictionary Based on the Language Resources on the Web for Mecab, https://github.com/neologd/mecab-ipadic-neologd (2016年5月21日現在)
- 8)scikit-learn, Machine Learning in Python : http://scikit-learn.org (2016年5月21日現在)
1988年生まれ.2011年慶應義塾大学理工学部管理工学科を卒業,2013年同大理工学研究科前期博士課程修了.在学中にConnehito(株)を創業,取締役.
櫻井 彰人(正会員)sakurai@ae.keio.ac.jp1975年東京大学工学部計数工学科卒業,1977年同大学院情報工学研究科修了,1977年(株)日立製作所入社那珂工場配属,1989年同基礎研究所,1996年同中央研究所,1998年北陸先端科学技術大学院大学教授を経て,2001年慶應義塾大学理工学部教授となる,機械学習, データ解析, 人工神経回路網を専門とする,博士(工学).
採録決定:2016年9月28日
編集担当:福田 晃(九州大学大学院)