
(邦訳:最適なチェックポイント・リスタートのための設計及び実装)
| 佐藤 賢斗 東京工業大学学術国際情報センター 科学研究費研究員 |
[背景]超並列エクサスケール・スパコン
[問題]システム故障による信頼性の低下の問題
[貢献]スパコンにおける耐故障技術の向上
[問題]システム故障による信頼性の低下の問題
[貢献]スパコンにおける耐故障技術の向上
科学技術分野においてシミュレーションは理論・実験に続く「第3の手法」として盛んに行われている.その基盤としてのスーパーコンピュータ(スパコン)が利用されており,近年さまざまな要素技術の進歩により,年々その規模とスピードが指数的に上昇している.たとえば,東京工業大学における TSUBAME2.5は2014年に置いて単精度性能が17ペタフロップス (10の15乗)と国内最大の性能を有しているが,さらに2020年頃にはエクサ(10の18乗)フロップスのマシンが登場すると目されている.
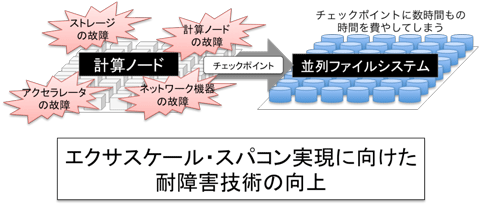
しかし,計算ノードや搭載されるCPU,GPU,メモリなどのデバイス,また,それらを繋ぐネットワーク機器などの多種多様なコンポーネントの指数的増加に伴い,機器の故障などによる障害発生頻度が増大している.これにより,障害・回復時間が実計算の何十倍ともなり・マシンが実質的に動作しなくなることが危惧されている.このように,エクサ・スケールのスパコンの実現は容易なことではない.実際,東京工業大学のTSUBAME2.0,米国オークリッジ国立研究所のJaguar,同研究所のTitanや米国ローレンス・リバモア国立研究所のSequoiaなどのスーパーコンピュータでは,1日平均2〜3回の障害が発生している.エクサ・スケールのスパコンでは100倍以上のコンポーネント数の増加が予測されており,仮に各コンポーネントの信頼性が数倍にできたとしても,現在のシステムと比べ障害発生率は数十倍近くなり,すべてのコンポーネントが正常に稼働する時間間隔が平均で数十分以下足らずになる.
このため,スパコン上で科学技術アプリケーションの長時間実行では,チェックポイント・リスタートという技術が広く利用されている.これは,アプリケーションの状態や途中結果 (チェックポイント) を,信頼性の高い並列ファイルシステムへ定期的に保存し,障害が発生した場合,最新のチェックポイントから計算を再開(リスタート)させる方法である.しかし,エクサスケール・スパコンでは,膨大な量のチェックポイントを保存する必要があるため,チェックポイントの時間だけで数時間かかってしまう.そのため,シミュレーションの時間の大半をチェックポイントやリスタートに費やしてしまい,計算が実質進まなくなると危惧されている.このため,本研究では,チェックポイントの時間を隠蔽するための非同期かつ階層型チェックポイント・リスタート,および,高速チェックポイントと自動復旧機構を備えた,耐故障通信ライブラリ,さらに,高速かつ高信頼型ストレージ・アーキテクチャの提案を行った.
しかし,計算ノードや搭載されるCPU,GPU,メモリなどのデバイス,また,それらを繋ぐネットワーク機器などの多種多様なコンポーネントの指数的増加に伴い,機器の故障などによる障害発生頻度が増大している.これにより,障害・回復時間が実計算の何十倍ともなり・マシンが実質的に動作しなくなることが危惧されている.このように,エクサ・スケールのスパコンの実現は容易なことではない.実際,東京工業大学のTSUBAME2.0,米国オークリッジ国立研究所のJaguar,同研究所のTitanや米国ローレンス・リバモア国立研究所のSequoiaなどのスーパーコンピュータでは,1日平均2〜3回の障害が発生している.エクサ・スケールのスパコンでは100倍以上のコンポーネント数の増加が予測されており,仮に各コンポーネントの信頼性が数倍にできたとしても,現在のシステムと比べ障害発生率は数十倍近くなり,すべてのコンポーネントが正常に稼働する時間間隔が平均で数十分以下足らずになる.
このため,スパコン上で科学技術アプリケーションの長時間実行では,チェックポイント・リスタートという技術が広く利用されている.これは,アプリケーションの状態や途中結果 (チェックポイント) を,信頼性の高い並列ファイルシステムへ定期的に保存し,障害が発生した場合,最新のチェックポイントから計算を再開(リスタート)させる方法である.しかし,エクサスケール・スパコンでは,膨大な量のチェックポイントを保存する必要があるため,チェックポイントの時間だけで数時間かかってしまう.そのため,シミュレーションの時間の大半をチェックポイントやリスタートに費やしてしまい,計算が実質進まなくなると危惧されている.このため,本研究では,チェックポイントの時間を隠蔽するための非同期かつ階層型チェックポイント・リスタート,および,高速チェックポイントと自動復旧機構を備えた,耐故障通信ライブラリ,さらに,高速かつ高信頼型ストレージ・アーキテクチャの提案を行った.
(2014年5月31日受付)