
| 浦 晃 (株)富士通研究所 |
[背景]多様なアプリケーションにおける並列計算の重要性の高まり
[問題]タスクに依存関係や大きさのばらつきのある計算の並列化
[貢献]コンピュータ将棋で大規模計算環境を活用するための知見を提供
並列計算環境の並列性は年々増加しており,大規模な計算環境はより身近なものになってきている.大規模計算環境を有効に活用するためには,さまざまなアプリケーションに対して,大規模計算環境を用いた研究が行われるべきである.本研究では,アプリケーションとしてコンピュータ将棋プレイヤを対象に,機械学習と探索の両方の観点から,大規模計算環境を活用する手法を提案した.そして,数百コア以上からなるクラスタ環境を用いた実験により,提案手法の多くについてその有効性を示した.
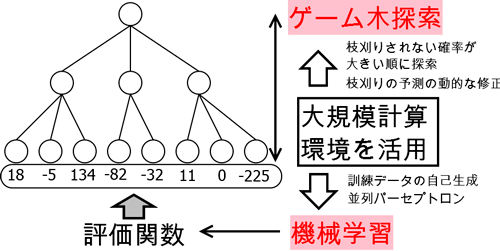
コンピュータ将棋では,ゲーム木を探索することによって指し手を決定する.ゲーム木探索では,先読みをある深さで打ち切り,その局面をリーフノードとみなす.このとき,局面の有利不利の度合いを評価関数を用いて推定し,数値化する.強いプログラムを実現するためには,評価関数の精度を向上をさせることと,探索を高速化して先読みの深さを大きくすることの二点が重要となる.
近年のコンピュータ将棋の評価関数のパラメータ調整には機械学習が用いられる.特に,プロの棋譜から,局面とその指し手を訓練データとして用いる手法が主流となっている.本研究では,評価関数の学習に大規模計算環境を活用するために,以下の2つの手法を提案した.まず,指し手のついていない局面を自動的に生成し,それをコンピュータプレイヤに探索させることで得られる指し手と合わせることで,訓練データを自己生成し,プロの棋譜に追加することを提案した.十分良い指し手を得るために,1局面あたり1コアで約2分かかる探索を百万以上の局面について行った.実験の結果,生成する局面を適切に選べば,訓練データの自己生成により,プレイヤの強さを向上させることができることを示した.次に,学習アルゴリズムであるパーセプトロンの並列化手法を評価関数の学習に適用することを提案し,学習時間を短縮できることを示した.このとき,評価関数の学習中には探索が実行されるため,タスクの大きさがばらつきやすいことが,さらなる速度向上を妨げている主な原因だと分かった.
コンピュータ将棋では,ゲーム木の探索手法として,αβアルゴリズムが用いられる.αβアルゴリズムはすでに探索した部分木の結果を用いて枝刈りを行うアルゴリズムであるため,各部分木の探索に依存関係があり,並列化が難しい.本研究では,大規模計算環境を用いてαβアルゴリズムを効率的に並列化するために以下の2つの手法を提案した.まず,各部分木が枝刈りされない確率を見積り,この確率が大きい部分木から優先的に探索する手法を提案した.シミュレーションを用いた実験を通して,計算環境が大規模になった場合には有効である可能性があることが分かった.次に,枝刈りされない部分木の予測に探索途中の結果を反映させる既存手法を,大規模計算環境に適用することを提案した.最大で1,536コアを用いた実験を通して,途中の結果を用いることによって探索時間を半分程度に短縮できることを示した.さらに,速度向上の妨げとなっている要因の詳細な分析も行った.
コンピュータ将棋では,ゲーム木を探索することによって指し手を決定する.ゲーム木探索では,先読みをある深さで打ち切り,その局面をリーフノードとみなす.このとき,局面の有利不利の度合いを評価関数を用いて推定し,数値化する.強いプログラムを実現するためには,評価関数の精度を向上をさせることと,探索を高速化して先読みの深さを大きくすることの二点が重要となる.
近年のコンピュータ将棋の評価関数のパラメータ調整には機械学習が用いられる.特に,プロの棋譜から,局面とその指し手を訓練データとして用いる手法が主流となっている.本研究では,評価関数の学習に大規模計算環境を活用するために,以下の2つの手法を提案した.まず,指し手のついていない局面を自動的に生成し,それをコンピュータプレイヤに探索させることで得られる指し手と合わせることで,訓練データを自己生成し,プロの棋譜に追加することを提案した.十分良い指し手を得るために,1局面あたり1コアで約2分かかる探索を百万以上の局面について行った.実験の結果,生成する局面を適切に選べば,訓練データの自己生成により,プレイヤの強さを向上させることができることを示した.次に,学習アルゴリズムであるパーセプトロンの並列化手法を評価関数の学習に適用することを提案し,学習時間を短縮できることを示した.このとき,評価関数の学習中には探索が実行されるため,タスクの大きさがばらつきやすいことが,さらなる速度向上を妨げている主な原因だと分かった.
コンピュータ将棋では,ゲーム木の探索手法として,αβアルゴリズムが用いられる.αβアルゴリズムはすでに探索した部分木の結果を用いて枝刈りを行うアルゴリズムであるため,各部分木の探索に依存関係があり,並列化が難しい.本研究では,大規模計算環境を用いてαβアルゴリズムを効率的に並列化するために以下の2つの手法を提案した.まず,各部分木が枝刈りされない確率を見積り,この確率が大きい部分木から優先的に探索する手法を提案した.シミュレーションを用いた実験を通して,計算環境が大規模になった場合には有効である可能性があることが分かった.次に,枝刈りされない部分木の予測に探索途中の結果を反映させる既存手法を,大規模計算環境に適用することを提案した.最大で1,536コアを用いた実験を通して,途中の結果を用いることによって探索時間を半分程度に短縮できることを示した.さらに,速度向上の妨げとなっている要因の詳細な分析も行った.
(2014年5月31日受付)