
(邦訳:構文・意味解析に対するニューラルネットワークを利用した手法)
| 栗田 修平 理化学研究所革新知能統合研究センター(AIP) 特別研究員 |
キーワード
| 自然言語処理 | 構文解析 | 省略・意味解析 | 深層学習 |
[背景]深層学習における統合的な構文解析と意味解析
[問題]既存コーパスにおけるデータサイズや隠れた構造による制約
[貢献]深層統合モデルとラベルなしコーパスを利用する学習の提案
[貢献]深層統合モデルとラベルなしコーパスを利用する学習の提案
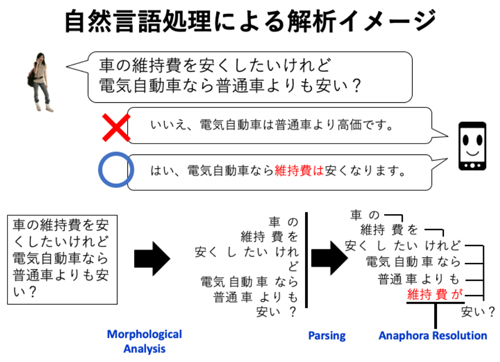
人間が扱う自然な文や文章を計算機にて取り扱うには,文を単語などの構造に分割し,品詞情報を付与し,係り受けや意味の構造を解析する必要がある.この単語分割,品詞付与のようなタスクは,典型的には自然言語処理の中で個別のタスクとして捉えられ,それぞれのタスクに対して機械学習手法などにより精度の向上が図られていた.実際に文を解析する際は,こうした個別タスクに対して最適化されたモデルを順番に繋いでゆき,前タスクの結果を次のタスクの入力とすることで最終的な解析結果を得ていた.また,このような個別タスクでは,それぞれのタスクに対応する形式のデータセットを用いて教師あり学習によりモデルが学習されていた.
このような限られたデータセットやタスクの中でモデルの優劣を評価する立場は,より実用的な解析モデルや,自然言語処理が目標とする人間に近い処理や理解を行うモデルの作成という点からは,かなり制約の大きい問題とも見て取れる.限られたドメインの中で学習を行う限り,モデルは自然言語の文で記述されている現象の表面的な部分のごく一部しか捉えて処理することができない.現在の自然言語処理は,いくつかのタスクを統合し知識を共有することや,ラベルなしコーパスから知識を取り入れる,もしくは,既存のタスクの中に隠れている知識を自発的に取り出して,既存データセットの枠組みの外側で学習を行うモデルが求められていると言える.近年では,深層学習と呼ばれる手法が自然言語処理の中でも広く用いられ,成功をおさめるようになった.深層学習では,多層で従来よりも大規模なニューラルネットワークを主にGPUなどの大規模な浮動小数演算が可能な素子を用いて学習を行う.しかし,先述のような特定のデータセットやタスクに縛られた学習を行っている限り,こうした深層学習的なアプローチにも限界があると思われる.
本研究では,このような個別タスクのデータセットに対する単純な最適化という描像ではなく,マルチタスク学習や統合モデル,ラベルなしコーパスを利用した学習など,既存のデータセットの枠組みのなるべく外側で学習を行うモデルを提案した.具体的には,本研究では以下の3つの試みを行った.まず,1つ目は,単語分割,品詞タグ付けなど順番に文の解析結果を繋いでゆく「パイプライン」と呼ばれる手法に対して,ニューラルネットワークを用いた統合モデルを提案した.2つ目は,常識的な知識に大きく依存する省略解析と呼ばれるタスクに対し,既存の限られたラベル付きコーパスの中では得られる精度に限界があるとして,ラベルなしコーパスを使用した学習方法を提案した.この方法により,モデルは限られた既存コーパスにない用例による学習も行えるようになった.3つ目は,意味依存構造解析と呼ばれるタスクに対し,深層強化学習によりモデルがタスク内部で平易と思われる個所から解析を行う手法を提案した.特にこの手法では,解析の結果,モデルが既存のデータセット内の構造を考慮しながら解析を行っていることを示唆する結果が得られた.これらの研究は,本研究の3つの章にまとめられ,それぞれ中国語に対する統合構文解析モデルの提案,日本語省略解析に対するラベルなしコーパスを用いた学習,英語意味依存構造解析に対する深層強化学習による平易優先学習としてまとめられている.
このような限られたデータセットやタスクの中でモデルの優劣を評価する立場は,より実用的な解析モデルや,自然言語処理が目標とする人間に近い処理や理解を行うモデルの作成という点からは,かなり制約の大きい問題とも見て取れる.限られたドメインの中で学習を行う限り,モデルは自然言語の文で記述されている現象の表面的な部分のごく一部しか捉えて処理することができない.現在の自然言語処理は,いくつかのタスクを統合し知識を共有することや,ラベルなしコーパスから知識を取り入れる,もしくは,既存のタスクの中に隠れている知識を自発的に取り出して,既存データセットの枠組みの外側で学習を行うモデルが求められていると言える.近年では,深層学習と呼ばれる手法が自然言語処理の中でも広く用いられ,成功をおさめるようになった.深層学習では,多層で従来よりも大規模なニューラルネットワークを主にGPUなどの大規模な浮動小数演算が可能な素子を用いて学習を行う.しかし,先述のような特定のデータセットやタスクに縛られた学習を行っている限り,こうした深層学習的なアプローチにも限界があると思われる.
本研究では,このような個別タスクのデータセットに対する単純な最適化という描像ではなく,マルチタスク学習や統合モデル,ラベルなしコーパスを利用した学習など,既存のデータセットの枠組みのなるべく外側で学習を行うモデルを提案した.具体的には,本研究では以下の3つの試みを行った.まず,1つ目は,単語分割,品詞タグ付けなど順番に文の解析結果を繋いでゆく「パイプライン」と呼ばれる手法に対して,ニューラルネットワークを用いた統合モデルを提案した.2つ目は,常識的な知識に大きく依存する省略解析と呼ばれるタスクに対し,既存の限られたラベル付きコーパスの中では得られる精度に限界があるとして,ラベルなしコーパスを使用した学習方法を提案した.この方法により,モデルは限られた既存コーパスにない用例による学習も行えるようになった.3つ目は,意味依存構造解析と呼ばれるタスクに対し,深層強化学習によりモデルがタスク内部で平易と思われる個所から解析を行う手法を提案した.特にこの手法では,解析の結果,モデルが既存のデータセット内の構造を考慮しながら解析を行っていることを示唆する結果が得られた.これらの研究は,本研究の3つの章にまとめられ,それぞれ中国語に対する統合構文解析モデルの提案,日本語省略解析に対するラベルなしコーパスを用いた学習,英語意味依存構造解析に対する深層強化学習による平易優先学習としてまとめられている.
(2019年5月31日受付)