
| 阿部 博 (株)レピダム 研究員/ココン(株)技術研究室 主任研究員/情報通信研究機構 協力研究員/北陸先端科学技術大学院大学 プロジェクト研究員 |
キーワード
| ログ検索エンジン | 分散システム | アノマリ検知 |
[背景]ビッグデータ時代のシステム管理者が直面するトラブル対応負荷の増大
[問題]管理者がトラブル対応に時間を割けない複雑なシステムと管理負荷
[貢献]シンプルで高速な検索システムによる管理業務への集中と自動異常検知
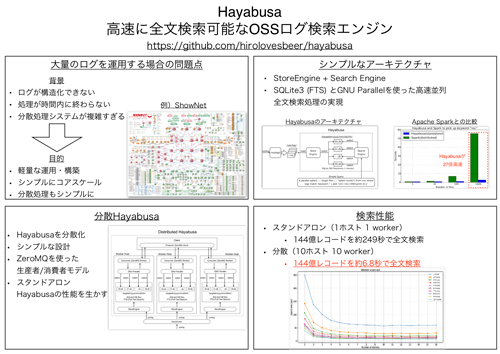
ネットワーク管理者は日々ネットワークの健全性を評価し,トラブルが発生した場合にはさまざまな角度から分析を行いその原因を特定し安定した運用を実現している.そのため,ネットワークへと繋がる機器から生成される多種に渡るデータを収集する必要がある.障害が発生した場合に,管理者は可能な限りトラブルの原因を早急に調査し解決しなければならない.日々対応するトラブルシューティング作業のために高速なログ検索システムを利用する場合があるが,複雑なクラスタを利用すると管理時間が増え,ネットワークを安定的に運用するという本質的な作業時間が削られる問題が発生する.「ログの蓄積」と「ログの検索」がシンプルに動作し,かつ複雑なクラスタを用いずに実現されるならば,管理者がシステムの管理に時間を割かれることはなくなり,トラブル対応に集中することができる.
本研究ではまず,大規模なネットワークを安定的に管理するための問題点を提議した.また,大規模ネットワークでの異常検知の問題とデータ量の問題,そこで収集される時系列データについて述べた.次に,大規模な時系列ログデータを処理する1つの実装として,Hayabusaを設計,評価し,スタンドアロン環境で高い検索性能を実現した.さらに,Hayabusaの性能を高めるため,分散版のHayabusaを設計,評価し,高い検索性能を実現した.そして,分散版Hayabusaの課題として問題を改良した新アーキテクチャを設計し評価を行い,その実装をOSSとして公開した.最後に,高速に集計データを取得可能なHayabusaの特性を生かすため,統計データを用いたアノマリ検知機構を提案し,大規模なイベントネットワークで取得した実データを用いて評価を行い,異常検出のための仕組みを実装した.
本研究では,大量なログデータを時系列データとして蓄積・検索可能なアーキテクチャとしてHayabusaを設計し,小規模な分散処理クラスタを用いることで高い検索処理性能を実現した.また,HayabusaがOSSとして公開されていることによりシステムがブラックボックス化せずに,オンプレミス環境やクラウド上であっても誰もが望む場所にシステムを構築し改良することが可能となった.
そして,ボリンジャーバンドを用いた異常検出アルゴリズムを実現し,有効性を評価した.これにより,ネットワーク管理者は大規模な実ネットワークにおいて,本手法を適用しネットワークの異常を発見することができる.
本研究では時系列ログデータに対するシステム最適化という実装を実現した.Hayabusaは,大量の時系列データをCPUのメニーコアに適した形で処理可能であり,今後訪れるであるメニーコア時代に追従可能なアーキテクチャの1つを実現した.異常検出における統計学を用いた手法の提案と実現,ならびに実データを用いた評価に関しては,特に実データの有用性を示す結果となり,本来運用データとしてしか用いられないデータをうまく研究課題として取り込んだ一例として示すことが可能である.
[貢献]シンプルで高速な検索システムによる管理業務への集中と自動異常検知
ネットワーク管理者は日々ネットワークの健全性を評価し,トラブルが発生した場合にはさまざまな角度から分析を行いその原因を特定し安定した運用を実現している.そのため,ネットワークへと繋がる機器から生成される多種に渡るデータを収集する必要がある.障害が発生した場合に,管理者は可能な限りトラブルの原因を早急に調査し解決しなければならない.日々対応するトラブルシューティング作業のために高速なログ検索システムを利用する場合があるが,複雑なクラスタを利用すると管理時間が増え,ネットワークを安定的に運用するという本質的な作業時間が削られる問題が発生する.「ログの蓄積」と「ログの検索」がシンプルに動作し,かつ複雑なクラスタを用いずに実現されるならば,管理者がシステムの管理に時間を割かれることはなくなり,トラブル対応に集中することができる.
本研究ではまず,大規模なネットワークを安定的に管理するための問題点を提議した.また,大規模ネットワークでの異常検知の問題とデータ量の問題,そこで収集される時系列データについて述べた.次に,大規模な時系列ログデータを処理する1つの実装として,Hayabusaを設計,評価し,スタンドアロン環境で高い検索性能を実現した.さらに,Hayabusaの性能を高めるため,分散版のHayabusaを設計,評価し,高い検索性能を実現した.そして,分散版Hayabusaの課題として問題を改良した新アーキテクチャを設計し評価を行い,その実装をOSSとして公開した.最後に,高速に集計データを取得可能なHayabusaの特性を生かすため,統計データを用いたアノマリ検知機構を提案し,大規模なイベントネットワークで取得した実データを用いて評価を行い,異常検出のための仕組みを実装した.
本研究では,大量なログデータを時系列データとして蓄積・検索可能なアーキテクチャとしてHayabusaを設計し,小規模な分散処理クラスタを用いることで高い検索処理性能を実現した.また,HayabusaがOSSとして公開されていることによりシステムがブラックボックス化せずに,オンプレミス環境やクラウド上であっても誰もが望む場所にシステムを構築し改良することが可能となった.
そして,ボリンジャーバンドを用いた異常検出アルゴリズムを実現し,有効性を評価した.これにより,ネットワーク管理者は大規模な実ネットワークにおいて,本手法を適用しネットワークの異常を発見することができる.
本研究では時系列ログデータに対するシステム最適化という実装を実現した.Hayabusaは,大量の時系列データをCPUのメニーコアに適した形で処理可能であり,今後訪れるであるメニーコア時代に追従可能なアーキテクチャの1つを実現した.異常検出における統計学を用いた手法の提案と実現,ならびに実データを用いた評価に関しては,特に実データの有用性を示す結果となり,本来運用データとしてしか用いられないデータをうまく研究課題として取り込んだ一例として示すことが可能である.
| https://github.com/hirolovesbeer/hayabusa https://github.com/hirolovesbeer/hayabusa2 |
(2019年5月31日受付)