
| 新井 淳也 日本電信電話(株)ソフトウェアイノベーションセンタ 研究員 |
キーワード
| ビッグデータ | グラフ処理 | アルゴリズム |
[背景]「つながり」を表現するデータ(グラフ)の大規模化
[問題]グラフからの情報抽出に要求される高い計算コスト
[貢献]メモリアクセスと無駄な計算を削減するアルゴリズム
人々の活動や実世界のセンサから生成される大規模データ,すなわちいわゆるビッグデータは多種多様な情報から成る.その中にはソーシャルネットワーキングサービス (SNS) における友人関係に代表されるような,事物間の「つながり」に着目して表現される情報も含まれる.そのような情報は「グラフ」と呼ばれ,柔軟性が高く,表現できる情報が幅広いことから広く用いられている.グラフから情報を得るための検索問合せ(クエリ)ではデータ全体に対するまばらで不規則なアクセスが生じることから,効率的に処理するためにはメモリ上にすべてのデータを置く必要がある.したがって大規模なグラフの処理は大容量のメモリを要求する.たとえばFacebookは2000億以上の友人関係を含むと言われており,単純なつながりの情報だけで3テラバイト以上,さらに人物や各つながりを説明するプロパティ情報によってさらに何倍ものメモリを搭載した計算機が必要となる.そのような計算機の導入は高コストであったが,近年はパブリッククラウドのサービスが充実し大容量メモリの計算環境を安価に利用できるようになった.ますます大規模化していくグラフデータに対応するため,本研究ではクラウド環境におけるグラフクエリ処理に焦点を当てた.
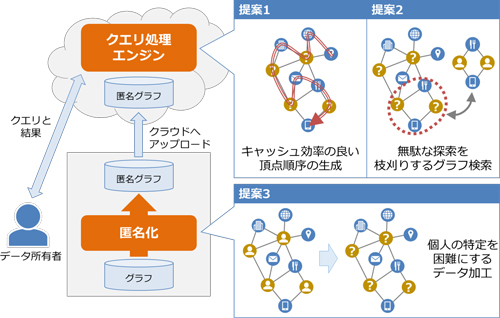
クラウド環境の利用にあたってはグラフに含まれるパーソナルデータの流出リスクと個人情報保護法などの法的制約に配慮する必要がある.そこで本研究では個人の特定が困難になるようなデータの書き換え(匿名化)を通じたクラウド利用の枠組みを考えた.具体的には,データ所有者は自身の計算環境においてグラフを匿名化し,それをクラウド環境へアップロードする.クラウド環境には高速なクエリ処理エンジンを配備し,匿名化されたデータに基づいてクエリを処理する.この枠組みを大規模なデータに対して適用するためには高速なクエリ処理エンジンと匿名化プログラムが必要である.しかしクエリ処理では前述のように不規則なメモリアクセスが発生し,さらに処理結果に貢献しない無駄な探索が性能を低下させる.また匿名化においては,匿名性を得るための書き換え量を抑えなければ匿名化前とかけ離れたデータになってしまう.書き換え量を抑えつつ高速に処理することは一般に困難である.
そこで本研究では高速なクエリ処理と匿名化を可能にするための3つの新しいアルゴリズムを提案した.まず高速なクエリ処理エンジンを実現するため,1つ目の提案においてグラフの頂点順序を最適化し,高速にアクセス可能なCPUのキャッシュメモリを効果的に利用する.また2つ目の提案において,一度行った無駄な探索を二度繰り返さないよう枝刈りする.さらに匿名化では,3つ目の提案においてデータのクラスタ構造を捉えることで書き換え量の削減と高速処理を両立する.最後にそれぞれのアルゴリズムについて実験によってその有効性を確認した.
[貢献]メモリアクセスと無駄な計算を削減するアルゴリズム
人々の活動や実世界のセンサから生成される大規模データ,すなわちいわゆるビッグデータは多種多様な情報から成る.その中にはソーシャルネットワーキングサービス (SNS) における友人関係に代表されるような,事物間の「つながり」に着目して表現される情報も含まれる.そのような情報は「グラフ」と呼ばれ,柔軟性が高く,表現できる情報が幅広いことから広く用いられている.グラフから情報を得るための検索問合せ(クエリ)ではデータ全体に対するまばらで不規則なアクセスが生じることから,効率的に処理するためにはメモリ上にすべてのデータを置く必要がある.したがって大規模なグラフの処理は大容量のメモリを要求する.たとえばFacebookは2000億以上の友人関係を含むと言われており,単純なつながりの情報だけで3テラバイト以上,さらに人物や各つながりを説明するプロパティ情報によってさらに何倍ものメモリを搭載した計算機が必要となる.そのような計算機の導入は高コストであったが,近年はパブリッククラウドのサービスが充実し大容量メモリの計算環境を安価に利用できるようになった.ますます大規模化していくグラフデータに対応するため,本研究ではクラウド環境におけるグラフクエリ処理に焦点を当てた.
クラウド環境の利用にあたってはグラフに含まれるパーソナルデータの流出リスクと個人情報保護法などの法的制約に配慮する必要がある.そこで本研究では個人の特定が困難になるようなデータの書き換え(匿名化)を通じたクラウド利用の枠組みを考えた.具体的には,データ所有者は自身の計算環境においてグラフを匿名化し,それをクラウド環境へアップロードする.クラウド環境には高速なクエリ処理エンジンを配備し,匿名化されたデータに基づいてクエリを処理する.この枠組みを大規模なデータに対して適用するためには高速なクエリ処理エンジンと匿名化プログラムが必要である.しかしクエリ処理では前述のように不規則なメモリアクセスが発生し,さらに処理結果に貢献しない無駄な探索が性能を低下させる.また匿名化においては,匿名性を得るための書き換え量を抑えなければ匿名化前とかけ離れたデータになってしまう.書き換え量を抑えつつ高速に処理することは一般に困難である.
そこで本研究では高速なクエリ処理と匿名化を可能にするための3つの新しいアルゴリズムを提案した.まず高速なクエリ処理エンジンを実現するため,1つ目の提案においてグラフの頂点順序を最適化し,高速にアクセス可能なCPUのキャッシュメモリを効果的に利用する.また2つ目の提案において,一度行った無駄な探索を二度繰り返さないよう枝刈りする.さらに匿名化では,3つ目の提案においてデータのクラスタ構造を捉えることで書き換え量の削減と高速処理を両立する.最後にそれぞれのアルゴリズムについて実験によってその有効性を確認した.
| https://git.io/rabbit (提案1の実装) |
(2019年5月31日受付)