
(邦訳:個人情報の安全かつ柔軟な公開共有を可能とする情報流通基盤に関する研究)
| 中村 優一 早稲田大学グローバルエデュケーションセンター 講師 |
キーワード
| データ公開 | プライバシ保護 | 匿名化 |
[背景]分野横断的なデータ利活用による新たな知見の獲得への期待
[問題]データ利活用におけるプライバシ保護の問題
[貢献]プライバシに配慮したデータ公開共有のための情報流通基盤および関連技術の提案
突然だが,皆さんの普段の行動を思い出してほしい.TwitterやFacebookなどのソーシャルネットワーキングサービス(SNS)では知り合い同士で近況を報告し合い,お店では会員カードやクーポンを使っておトクに買い物を楽しんでいる.旅行に行くときは,検索サイトを使って旅先の見どころやイベント情報を事前に調べるかもしれない.これらの共通点は,我々が「情報」に価値を見出してサービスを利用していることである.この「情報の価値」はサービスを提供する企業にも重要で,実は私たちがサービスを利用した際に生まれる情報を収集し活用している.たとえばコンビニは同じブランドでも店舗によって品揃えが異なるが,これは顧客の購買行動を分析し,店舗ごとに,地域色を反映した品揃えにカスタマイズしているためである.特に会員の買い物は過去の購買履歴までさかのぼれる上,年齢や性別など会員自身の情報も含まれるため,より詳細で有益な分析が可能となる.このようなデータ利用はサービス業界に限らず金融業界や製造業界などさまざまな分野でも同様に実施されており,それぞれの分野で大量に集められたデータ(ビッグデータ)が分析され,ビジネスや研究に活用されている.ここで,もし企業や分野を超えてデータを共有できれば,今までよりもっと面白く新しい知見を得られるかもしれない.
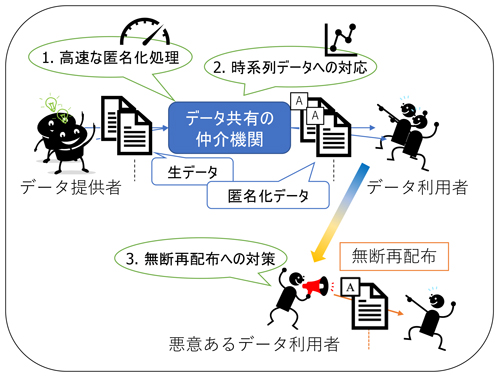
このような期待に反し,異分野間でのデータ共有には乗り越えるべき壁がある.それはデータプライバシの問題だ.具体的には,ビッグデータの中には,いわゆる個人情報が含まれている可能性があるため,データ共有によって,その個人のプライバシを侵害するかもしれない,という懸念である.もしこの問題を解決しながらデータを公開共有できるような基盤があれば,異分野間の情報のコラボレーションが促進されるであろう.本研究ではこの基盤を具体的な枠組みとともに提案しながら,この基盤の実現に向けて必要な機能についても研究を進めている.
1つ目の機能は,高速な匿名化処理である.本研究ではプライバシを保護する手段として匿名化技術を採用している.匿名化は一般に,データをより抽象的な表現に書き換える技術で,これによって,特定のデータレコードに紐づく個人の同定を困難にする.提案基盤ではデータ共有の仲介役として受け取ったデータを匿名化してから共有するが,大量のデータの処理が必要な場合や早急なデータ共有な求められる場合などに,高速な匿名化処理が必要となる.本研究はハードウェアによる実装によって,匿名化処理の高速化を図った.
2つ目の機能は,一般的なデータ形式の1つである時系列データへの対応である.時系列データは電力計から定期的に送られてくる電力消費データなど,値と取得時刻のペアの集まりである.時系列データの特徴は,値そのものだけにではなく,「ある日の電気の使い方」のような複数の値の連なりにも意味がある,という点だ.本研究では,この「連なり」を残しながらデータを匿名化する手法を提案した.
安全なデータ共有のためには,データの共有後についても考慮が必要だ.匿名化されているとはいえ,データの無断再配布は許されない.しかし複数のデータ利用者が同じ条件でデータを要求した場合,配布されるデータは利用者間で同一となるため,無断再配布元を特定できない.この問題に対し,本研究では第三の機能として,データ共有基盤からのデータ共有先を識別する情報を匿名化データに埋め込む手法を提案した.この手法によって,無断再配布されたデータから出所を識別できるようになり,無断再配布元に対して適切に対応できるようになる.
博士論文では上記3つの提案手法について,それぞれ具体的な利用シーンを想定しながら性能を評価し,手法の有用性を示した.「安全なデータ共有に必要な実際的な手法とは何か?」を考えながら,今後も研究を進めていきたい.
[貢献]プライバシに配慮したデータ公開共有のための情報流通基盤および関連技術の提案
突然だが,皆さんの普段の行動を思い出してほしい.TwitterやFacebookなどのソーシャルネットワーキングサービス(SNS)では知り合い同士で近況を報告し合い,お店では会員カードやクーポンを使っておトクに買い物を楽しんでいる.旅行に行くときは,検索サイトを使って旅先の見どころやイベント情報を事前に調べるかもしれない.これらの共通点は,我々が「情報」に価値を見出してサービスを利用していることである.この「情報の価値」はサービスを提供する企業にも重要で,実は私たちがサービスを利用した際に生まれる情報を収集し活用している.たとえばコンビニは同じブランドでも店舗によって品揃えが異なるが,これは顧客の購買行動を分析し,店舗ごとに,地域色を反映した品揃えにカスタマイズしているためである.特に会員の買い物は過去の購買履歴までさかのぼれる上,年齢や性別など会員自身の情報も含まれるため,より詳細で有益な分析が可能となる.このようなデータ利用はサービス業界に限らず金融業界や製造業界などさまざまな分野でも同様に実施されており,それぞれの分野で大量に集められたデータ(ビッグデータ)が分析され,ビジネスや研究に活用されている.ここで,もし企業や分野を超えてデータを共有できれば,今までよりもっと面白く新しい知見を得られるかもしれない.
このような期待に反し,異分野間でのデータ共有には乗り越えるべき壁がある.それはデータプライバシの問題だ.具体的には,ビッグデータの中には,いわゆる個人情報が含まれている可能性があるため,データ共有によって,その個人のプライバシを侵害するかもしれない,という懸念である.もしこの問題を解決しながらデータを公開共有できるような基盤があれば,異分野間の情報のコラボレーションが促進されるであろう.本研究ではこの基盤を具体的な枠組みとともに提案しながら,この基盤の実現に向けて必要な機能についても研究を進めている.
1つ目の機能は,高速な匿名化処理である.本研究ではプライバシを保護する手段として匿名化技術を採用している.匿名化は一般に,データをより抽象的な表現に書き換える技術で,これによって,特定のデータレコードに紐づく個人の同定を困難にする.提案基盤ではデータ共有の仲介役として受け取ったデータを匿名化してから共有するが,大量のデータの処理が必要な場合や早急なデータ共有な求められる場合などに,高速な匿名化処理が必要となる.本研究はハードウェアによる実装によって,匿名化処理の高速化を図った.
2つ目の機能は,一般的なデータ形式の1つである時系列データへの対応である.時系列データは電力計から定期的に送られてくる電力消費データなど,値と取得時刻のペアの集まりである.時系列データの特徴は,値そのものだけにではなく,「ある日の電気の使い方」のような複数の値の連なりにも意味がある,という点だ.本研究では,この「連なり」を残しながらデータを匿名化する手法を提案した.
安全なデータ共有のためには,データの共有後についても考慮が必要だ.匿名化されているとはいえ,データの無断再配布は許されない.しかし複数のデータ利用者が同じ条件でデータを要求した場合,配布されるデータは利用者間で同一となるため,無断再配布元を特定できない.この問題に対し,本研究では第三の機能として,データ共有基盤からのデータ共有先を識別する情報を匿名化データに埋め込む手法を提案した.この手法によって,無断再配布されたデータから出所を識別できるようになり,無断再配布元に対して適切に対応できるようになる.
博士論文では上記3つの提案手法について,それぞれ具体的な利用シーンを想定しながら性能を評価し,手法の有用性を示した.「安全なデータ共有に必要な実際的な手法とは何か?」を考えながら,今後も研究を進めていきたい.
(2019年5月29日受付)