
| 上垣外 英剛 NTTコミュニケーション科学基礎研究所協創情報研究部言語知能研究グループ リサーチアソシエイト |
[背景]実用的な翻訳のための高精度かつコンパクトな翻訳モデルの必要性
[問題]単語アライメントの誤りと翻訳モデルサイズの増大
[貢献]翻訳精度の向上および翻訳モデルサイズの削減
機械翻訳は,入力された文書を,目的の言語に自動で翻訳するという課題である.電子計算機が発明されて以降,機械翻訳に関するさまざまな研究が行われ,数多くの手法が開発されてきた.本研究ではその中でも統計的機械翻訳の枠組みに注目し,その構成要素の一つである,翻訳モデルに残された課題の解決を行う.
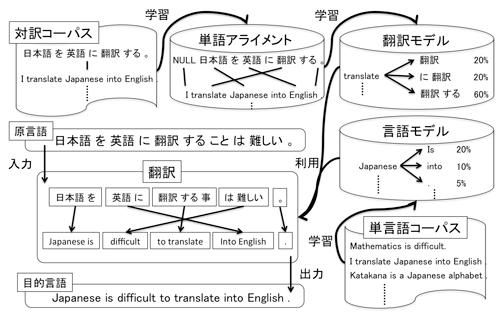
以下に統計的機械翻訳に基づく翻訳手法の一つである,フレーズベース翻訳の構成要素についての図を示す.下図に示すよう,統計的機械翻訳では,入力された原言語の文を目的言語の文に翻訳するために,言語モデルと翻訳モデルを使用する.言語モデルは,目的言語のみで構成される,単言語コーパスから学習される.一方,翻訳モデルは,あらかじめ両言語での文間の対応が与えられた,対訳コーパスを用いて学習が行われる.翻訳モデルの学習の際には,一般的に,単語間の対応である単語アライメントを先に学習し,その結果に基づき,フレーズなどの,より大きな単位での抽出と学習を行う.
本研究では主に翻訳モデルに焦点を当て,残された次の2つの課題について扱った.1つ目は,既存の単語アライメントの学習手法では,言語学的に遠い言語対において機能語と内容語の対応が誤り易いという課題である.2つ目は,単語アライメントを介した網羅的な抽出によって,翻訳モデル中に,翻訳時に使用しない,不要な対応が含まれることとなり,翻訳モデルのサイズが,特に階層型フレーズベース翻訳において増大してしまうという課題である.
1つ目の課題については,制約付きのEM学習法である事後確率正則化学習法の制約として,機能語と内容語を明示的に区別して扱うことが可能な制約を提案した.提案した制約は出現頻度に基づいて機能語と内容語を識別するため,対象とする言語に依存しない.評価の結果,提案手法は,従来手法である対称化制約と比較し,日本語と英語の言語対において,単語アライメント精度と翻訳精度が向上することを,自動評価において確認した.
2つ目の課題については,階層型Pitman-Yor過程に基づくバックオフを行うモデルを提案した.提案手法は,フレーズ対をより小さなフレーズ対で表現可能なため,従来のベイズ的手法では扱いにくかった単語数の多いフレーズ対についても,スパース性を回避して推定することが可能である.ドイツ語から英語への翻訳における自動評価の結果,提案手法はより少ないルールテーブルサイズで,従来の網羅的な抽出を行う手法と同等の翻訳精度を示すことを確認した.
上記のように,本研究では,統計的機械翻訳における翻訳モデルに存在している2つの課題に対し,教師なし学習に基づく手法による解決法を示し,その効果を確認し,結果について論じた.
今後はニューラルネットワークに基づく手法と提案手法の融合についても検討したい.
以下に統計的機械翻訳に基づく翻訳手法の一つである,フレーズベース翻訳の構成要素についての図を示す.下図に示すよう,統計的機械翻訳では,入力された原言語の文を目的言語の文に翻訳するために,言語モデルと翻訳モデルを使用する.言語モデルは,目的言語のみで構成される,単言語コーパスから学習される.一方,翻訳モデルは,あらかじめ両言語での文間の対応が与えられた,対訳コーパスを用いて学習が行われる.翻訳モデルの学習の際には,一般的に,単語間の対応である単語アライメントを先に学習し,その結果に基づき,フレーズなどの,より大きな単位での抽出と学習を行う.
本研究では主に翻訳モデルに焦点を当て,残された次の2つの課題について扱った.1つ目は,既存の単語アライメントの学習手法では,言語学的に遠い言語対において機能語と内容語の対応が誤り易いという課題である.2つ目は,単語アライメントを介した網羅的な抽出によって,翻訳モデル中に,翻訳時に使用しない,不要な対応が含まれることとなり,翻訳モデルのサイズが,特に階層型フレーズベース翻訳において増大してしまうという課題である.
1つ目の課題については,制約付きのEM学習法である事後確率正則化学習法の制約として,機能語と内容語を明示的に区別して扱うことが可能な制約を提案した.提案した制約は出現頻度に基づいて機能語と内容語を識別するため,対象とする言語に依存しない.評価の結果,提案手法は,従来手法である対称化制約と比較し,日本語と英語の言語対において,単語アライメント精度と翻訳精度が向上することを,自動評価において確認した.
2つ目の課題については,階層型Pitman-Yor過程に基づくバックオフを行うモデルを提案した.提案手法は,フレーズ対をより小さなフレーズ対で表現可能なため,従来のベイズ的手法では扱いにくかった単語数の多いフレーズ対についても,スパース性を回避して推定することが可能である.ドイツ語から英語への翻訳における自動評価の結果,提案手法はより少ないルールテーブルサイズで,従来の網羅的な抽出を行う手法と同等の翻訳精度を示すことを確認した.
上記のように,本研究では,統計的機械翻訳における翻訳モデルに存在している2つの課題に対し,教師なし学習に基づく手法による解決法を示し,その効果を確認し,結果について論じた.
今後はニューラルネットワークに基づく手法と提案手法の融合についても検討したい.
(2017年6月1日受付)