
(邦訳:意味・対話構造の統計的学習に基づく情報案内のための音声対話システム)
| 吉野 幸一郎 奈良先端科学技術大学院大学 特任助教 |
[背景]音声によるゴール指向・一問一答でない対話インタフェースへの期待
[問題]明確でないユーザの潜在的な情報要求に答える音声情報案内
[貢献]意味・対話構造の統計的学習を用いてユーザに適応的な情報案内を実現
本研究では,意味と対話構造の統計的学習に基づいて,ニュース記事などの文書に記述された内容に関する情報案内を行う音声対話システムを提案する.既存の音声対話システムは明確なユーザのゴールを想定していたが,こうした想定は常に成り立つわけではなく,ユーザはしばしば曖昧な欲求に基づいて対話を行っている.また,既存のシステムにおいてドメイン知識やタスク構造は手動で構築されており,異なるドメインへの適応の障害となっていた.そこで,ユーザの曖昧な欲求・発話を許容する,統計的学習に基づく情報案内システムを提案する.
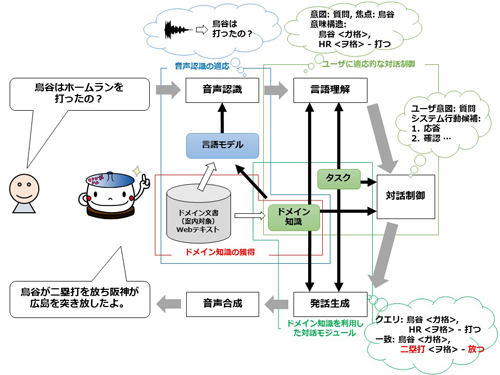
提案するシステムでは,ユーザの情報要求が明確でない場合に,自動で定義されたドメイン知識や対話の履歴を用いて,ユーザの潜在的な要求を探りつつ,関連する情報を提示する.このシステムが利用する意味構造を利用したドメイン知識は,ドメインコーパスから統計的学習により教師なしで獲得される.提案システムは,このドメイン知識に加えて,情報案内で必要な7種類の機能についてモジュールを定義し,これらを対話構造の統計的学習に基づく対話制御によって制御し対話を行う.
本研究は,述語項構造に着目した教師なしによるドメイン知識の獲得と,この知識を利用した音声対話システムの各モジュール:音声認識,対話モジュール,対話制御によって構成される.
述語項構造に着目したドメイン知識の獲得では,対話ドメインごとに異なる重要な意味構造(述語項構造)を,一般ドメインコーパスと特定ドメインコーパスの比較によって抽出する.
ドメイン知識を利用した音声認識の適応では,獲得されたドメイン知識を用いて音声認識における言語モデルの適応を行う.具体的には,Webから言語モデルの学習データとなる話し言葉文を獲得する際に,当該ドメインで重要な情報構造を持つ文を優先的に学習に利用することでモデルの構築を行う.
ドメイン知識を利用した対話モジュールでは,ユーザ発話の意味的な構造に対して,部分的に一致した情報を利用した応答を行う.構造そのもののの一致だけでなく,統計情報に基づく意味的な重要度・類似度を考慮して,柔軟な応答を行う.この枠組みは,情報案内における質問応答と情報推薦に利用される.
ユーザの焦点に適応的な統計的対話制御では,部分観測マルコフ決定過程(POMDP)を用いる.POMDPは広く対話制御に用いられているが,本研究では情報案内における対話制御の問題を,ユーザ発話に対する最適な応答モジュールの選択問題として定式化する.この際,一般的に用いられるユーザの発話意図に加えて,ユーザの焦点を利用することで,対話の文脈に応じたより適切な応答モジュールを選択することが可能になった.
これらの要素技術により,ユーザに適応的な情報案内システムを実現した.これら提案した枠組みはドメイン適応的に設計されており,さまざまな情報案内の問題に適用可能である.
提案するシステムでは,ユーザの情報要求が明確でない場合に,自動で定義されたドメイン知識や対話の履歴を用いて,ユーザの潜在的な要求を探りつつ,関連する情報を提示する.このシステムが利用する意味構造を利用したドメイン知識は,ドメインコーパスから統計的学習により教師なしで獲得される.提案システムは,このドメイン知識に加えて,情報案内で必要な7種類の機能についてモジュールを定義し,これらを対話構造の統計的学習に基づく対話制御によって制御し対話を行う.
本研究は,述語項構造に着目した教師なしによるドメイン知識の獲得と,この知識を利用した音声対話システムの各モジュール:音声認識,対話モジュール,対話制御によって構成される.
述語項構造に着目したドメイン知識の獲得では,対話ドメインごとに異なる重要な意味構造(述語項構造)を,一般ドメインコーパスと特定ドメインコーパスの比較によって抽出する.
ドメイン知識を利用した音声認識の適応では,獲得されたドメイン知識を用いて音声認識における言語モデルの適応を行う.具体的には,Webから言語モデルの学習データとなる話し言葉文を獲得する際に,当該ドメインで重要な情報構造を持つ文を優先的に学習に利用することでモデルの構築を行う.
ドメイン知識を利用した対話モジュールでは,ユーザ発話の意味的な構造に対して,部分的に一致した情報を利用した応答を行う.構造そのもののの一致だけでなく,統計情報に基づく意味的な重要度・類似度を考慮して,柔軟な応答を行う.この枠組みは,情報案内における質問応答と情報推薦に利用される.
ユーザの焦点に適応的な統計的対話制御では,部分観測マルコフ決定過程(POMDP)を用いる.POMDPは広く対話制御に用いられているが,本研究では情報案内における対話制御の問題を,ユーザ発話に対する最適な応答モジュールの選択問題として定式化する.この際,一般的に用いられるユーザの発話意図に加えて,ユーザの焦点を利用することで,対話の文脈に応じたより適切な応答モジュールを選択することが可能になった.
これらの要素技術により,ユーザに適応的な情報案内システムを実現した.これら提案した枠組みはドメイン適応的に設計されており,さまざまな情報案内の問題に適用可能である.
(2015年6月10日受付)