
(邦訳:遷移型依存構造解析改善のための技術に関する研究)
| 林 克彦 NTTコミュニケーション科学基礎研究所 |
[背景]統計的手法との融合により機械翻訳の性能が飛躍的に向上
[問題]構文構造が異なる言語間での機械翻訳
[貢献]構文構造解析器の高精度化と解析結果の重複除去法
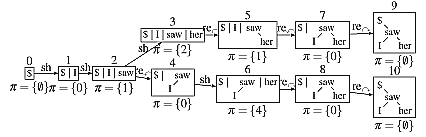
構文解析は言語処理分野において古くから研究されているが,その精度改善は未だに重要な研究課題となっている.また,1つの文に対して,複数の構文構造を出力しようとすると,一部の解析アルゴリズムでは同じ解析結果をいくつも出力してしまうという問題が残っている.これは分野ではSpurious Ambiguityと呼ばれている問題であり,図に示すような状況を指す.本研究では構文解析法の精度を向上させるために新たなアルゴリズムを提案すると同時に,その手法をさらに発展させることで,Spurious Ambiguityの問題を理論的に解決するための手法を提案している.
Spurious Ambiguityの問題を解消することの意義は複数の構文解析結果を機械翻訳システムへの入力とするような場合に,翻訳処理速度や性能改善の面で大きな貢献がある.従来の構文解析法は複数の構文解析結果のうち約20%から40%が他の候補と重複した解析結果となっていたが,提案法ではこのような重複した解析結果は全く含まれないことが保証されている.また,提案法による構文解析結果を機械翻訳へ応用したところ,性能の改善が確認された.
提案した手法は機械翻訳のみでなく,構文解析結果を利用する多くの言語処理システムにも貢献できるものであり,その価値は大きいと言える.
[問題]構文構造が異なる言語間での機械翻訳
[貢献]構文構造解析器の高精度化と解析結果の重複除去法
近年,統計的手法との融合により機械翻訳の性能は飛躍的に向上した.また,インターネットを介して,多様な言語間(英語,中国語,アラビア語,日本語など)の翻訳を瞬時に行うことができるサービスも多く提供されており,幅広いユーザから支持されている.
しかし,その一方で,日本語と英語のように言語の持つ構文構造が大きく異なる言語間では,その翻訳精度が不十分であることが指摘されている.言語間における構文構造の違いを明らかにし,それをモデル化するためには,文の構文を解析するための手法が必要となる.この問題はコンピュータサイエンスの分野でも良く知られている構文解析と呼ばれる研究領域である.
しかし,その一方で,日本語と英語のように言語の持つ構文構造が大きく異なる言語間では,その翻訳精度が不十分であることが指摘されている.言語間における構文構造の違いを明らかにし,それをモデル化するためには,文の構文を解析するための手法が必要となる.この問題はコンピュータサイエンスの分野でも良く知られている構文解析と呼ばれる研究領域である.
構文解析は言語処理分野において古くから研究されているが,その精度改善は未だに重要な研究課題となっている.また,1つの文に対して,複数の構文構造を出力しようとすると,一部の解析アルゴリズムでは同じ解析結果をいくつも出力してしまうという問題が残っている.これは分野ではSpurious Ambiguityと呼ばれている問題であり,図に示すような状況を指す.本研究では構文解析法の精度を向上させるために新たなアルゴリズムを提案すると同時に,その手法をさらに発展させることで,Spurious Ambiguityの問題を理論的に解決するための手法を提案している.
Spurious Ambiguityの問題を解消することの意義は複数の構文解析結果を機械翻訳システムへの入力とするような場合に,翻訳処理速度や性能改善の面で大きな貢献がある.従来の構文解析法は複数の構文解析結果のうち約20%から40%が他の候補と重複した解析結果となっていたが,提案法ではこのような重複した解析結果は全く含まれないことが保証されている.また,提案法による構文解析結果を機械翻訳へ応用したところ,性能の改善が確認された.
提案した手法は機械翻訳のみでなく,構文解析結果を利用する多くの言語処理システムにも貢献できるものであり,その価値は大きいと言える.
(2013年7月1日受付)